web安全
一元函数微分学
仿真
图书馆座位预约
htap
熵
python考级
资源
PDF合并与拆分
提取PDF内容
宠物
IO流的异常处理方式
数字IC
k8s
昇腾
大学生志愿者
性能
产品线
NDVI
AMD
中文分词
2024/4/11 21:13:25
es自定义分词器支持数字字母分词,中文分词器jieba支持添加禁用词和扩展词典
自定义分析器,分词器
PUT http://xxx.xxx.xxx.xxx:9200/test_index/
{"settings": {"analysis": {"analyzer": {"char_test_analyzer": {"tokenizer": "char_test_tokenizer","filter": [&…


中文编程入门(Lua5.4.6中文版)第九章 Lua 迭代器 参考种田游戏
迭代器(iterator)在游戏开发中扮演着重要角色,尤其是在Lua语言中。它是一种特殊的数据结构,能够逐个访问集合中的元素,犹如一位探险家穿越种田游戏的领土,逐一揭示各个城市与资源。
在Lua中,迭…
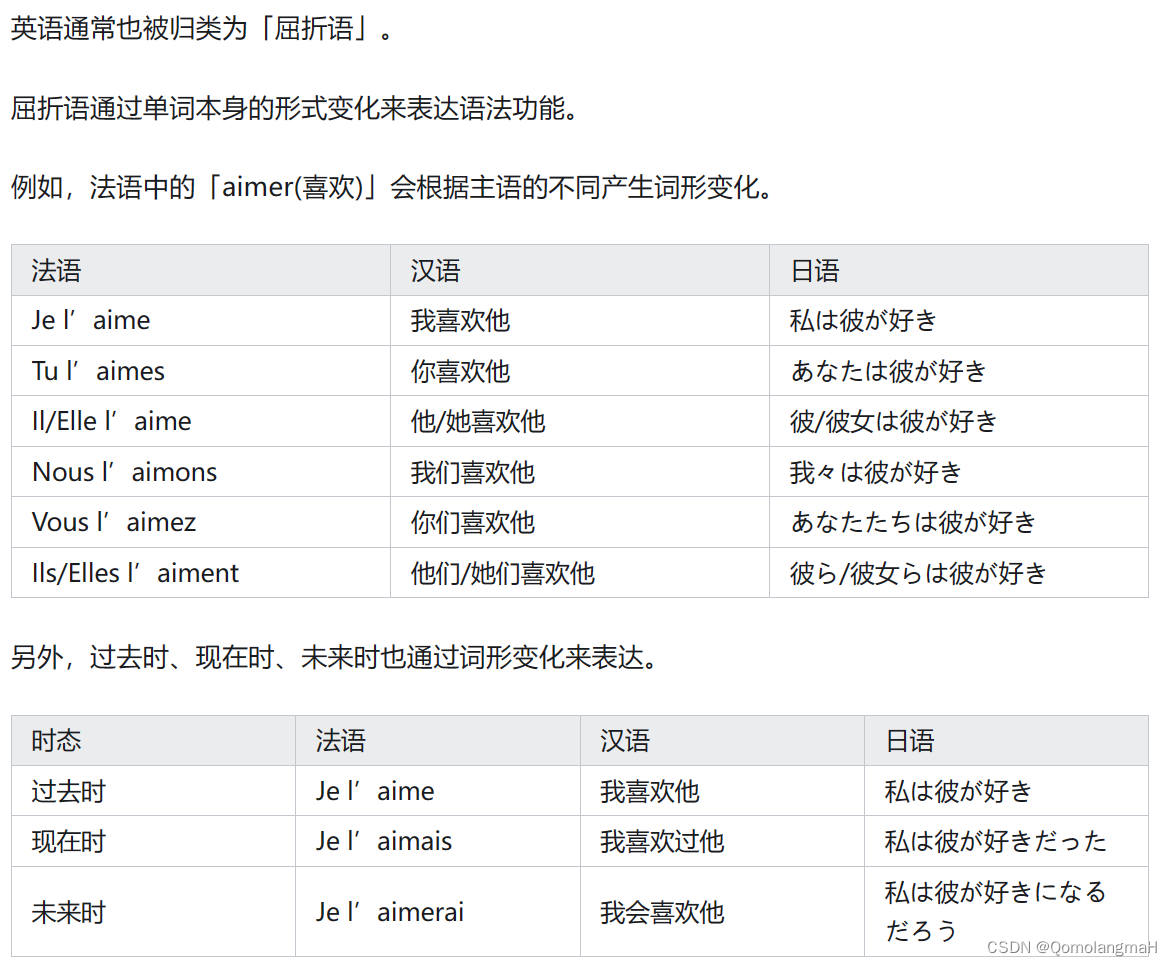
【自然语言处理】统计中文分词技术(一):1、分词与频度统计
文章目录 一、词与分词1、词 vs 词素2、世界语言分类 二、分词的原因与基本原因1、为什么要分词2、分词规范3、分词的主要难点-切分歧义如何排除切分歧义利用词法信息利用句法信息利用语义信息利用语用、语境信息 4、分词的主要难点-未登录词未登录词如何识别未登录词 三、分词…

Lua 和 Love 2d 教程 二十一点朴克牌 (上篇lua源码)
GitCode - 开发者的代码家园 Lua版完整原码 规则
庄家和玩家各发两张牌。庄家的第一张牌对玩家是隐藏的。
玩家可以拿牌(即拿另一张牌)或 停牌(即停止拿牌)。
如果玩家手牌的总价值超过 21,那么他们就爆掉了。
面牌…
如何实现电子合同管理系统与其他企业应用的无缝对接?
电子合同管理系统是一种利用信息技术来管理和执行合同的系统。随着企业数字化转型的推进,电子合同管理系统已经成为许多企业必备的工具之一。然而,要实现电子合同管理系统与其他企业应用的无缝对接,并不是一件容易的事情。
实现电子合同管理…
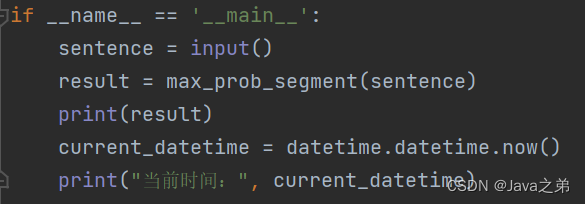
自然语言处理--概率最大中文分词
自然语言处理附加作业--概率最大中文分词
一、理论描述
中文分词是指将中文句子或文本按照语义和语法规则进行切分成词语的过程。在中文语言中,词语之间没有明显的空格或标点符号来分隔,因此需要通过分词工具或算法来实现对中文文本的分词处理。分词的…

基于结构化平均感知机的分词器Java实现
最近高产似母猪,写了个基于AP的中文分词器,在Bakeoff-05的MSR语料上F值有96.11%。最重要的是,只训练了5个迭代;包含语料加载等IO操作在内,整个训练一共才花费23秒。应用裁剪算法去掉模型中80%的特征后,F值才…

配置Hanlp自然语言处理进阶
中文分词
中文分词中有众多分词工具,如结巴、hanlp、盘古分词器、庖丁解牛分词等;其中庖丁解牛分词仅仅支持java,分词是HanLP最基础的功能,HanLP实现了许多种分词算法,每个分词器都支持特定的配置。接下来我将介绍如何…
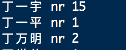
elasticsearch教程--中文分词器作用和使用
概述
本文都是基于elasticsearch安装教程 中的elasticsearch安装目录(/opt/environment/elasticsearch-6.4.0)为范例
环境准备
全新最小化安装的centos 7.5
elasticsearch 6.4.0
认识中文分词器
在博文elasticsearch分词器中提到elasticsearch能够快速的通过搜索词检…

chatgpt赋能python:Python下载jieba:优化中文分词的必备工具
Python下载jieba:优化中文分词的必备工具
在中文自然语言处理的领域中,分词是一项基础且重要的任务。jieba是一个优秀的中文分词组件,它支持三种分词模式,并且具有高效、准确、易用等优点。本文将介绍如何通过Python来下载jieba&…
Manticore Search 中文分词搜索入门
Manticore Search 3.1.0 版引入了一种基于ICU 文本分割算法的中文文本分割新方法,该算法遵循第二种方法 - 基于字典的分割。
ICU 是一组开源库,为软件应用程序提供 Unicode 和全球化支持。与许多其他功能一起,它解决了文本边界确定的任务。 ICU 算法在文…
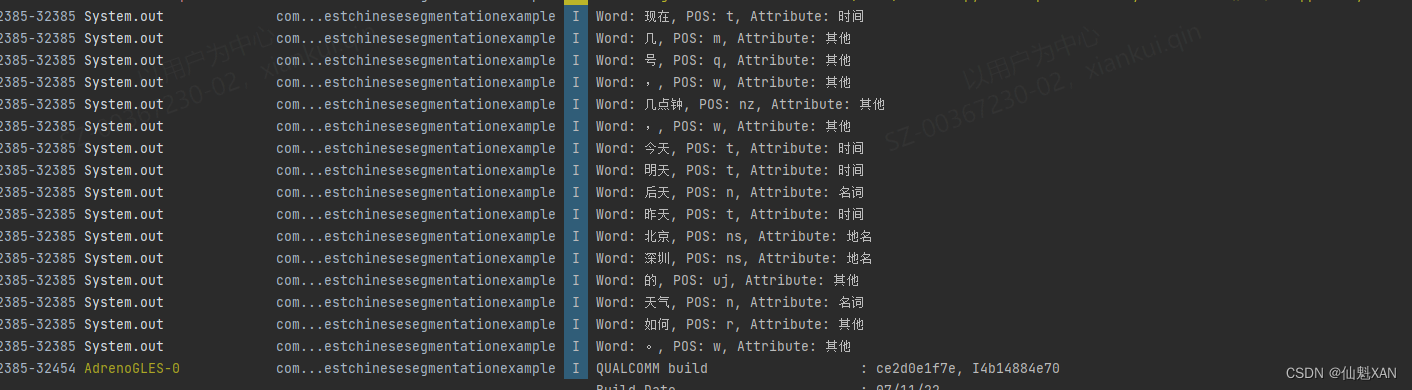
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 目录
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
一、简单介绍
二、实现原理…
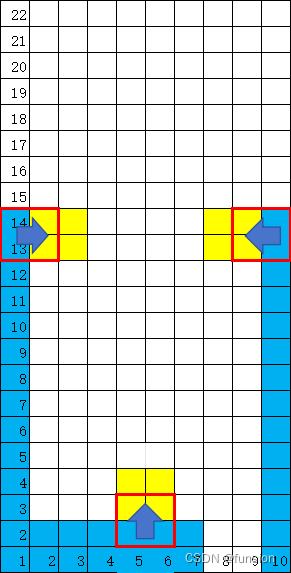
【容易不简单】love 2d Lua 俄罗斯方块超详细教程
源码已经更新在CSDN的码库里:
git clone https://gitcode.com/funsion/love2d-game.git 一直在找Lua 能快速便捷实现图形界面的软件,找了一堆,终于发现love2d是小而美的原生lua图形界面实现的方式。
并参考相关教程做了一个更详细的&#x…

Ansj与hanlp分词工具对比
一、Ansj
1、利用DicAnalysis可以自定义词库: 2、但是自定义词库存在局限性,导致有些情况无效:
比如:“不好用“的正常分词结果:“不好,用”。 (1)当自定义词库”好用“时…

简单有效的多标准中文分词详解
简单有效的多标准中文分词详解
本文介绍一种简洁优雅的多标准中文分词方案,可联合多个不同标准的语料库训练单个模型,同时输出多标准的分词结果。通过不同语料库之间的迁移学习提升模型的性能,在10个语料库上的联合试验结果优于绝大部分单独…
hanlp中文智能分词自动识别文字提取实例
需求:客户给销售员自己的个人信息,销售帮助客户下单,此过程需要销售人员手动复制粘贴收获地址,电话,姓名等等,一个智能的分词系统可以让销售人员一键识别以上各种信息
经过调研,找到了一下开源…

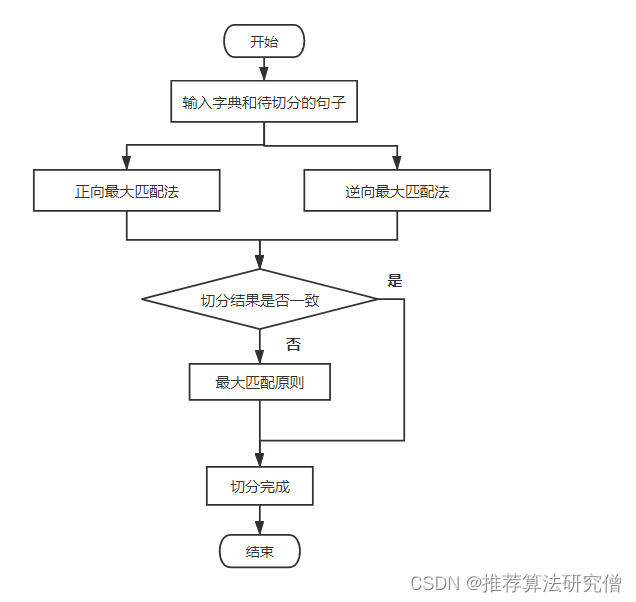
【Python自然语言处理】规则分词中正向、反向、双向最大匹配法的讲解及实战(超详细 附源码)
需要源码和字典集请点赞关注收藏后评论区留言私信~~~ 一、规则分词
规则分词核心内容是建立人工专家词典库,通过将语句切分出的单词串与专家词典库中的所有词语进行逐一匹配,匹配成功则进行对象词语切分,否则通过增加或者减少一个字继续比较…
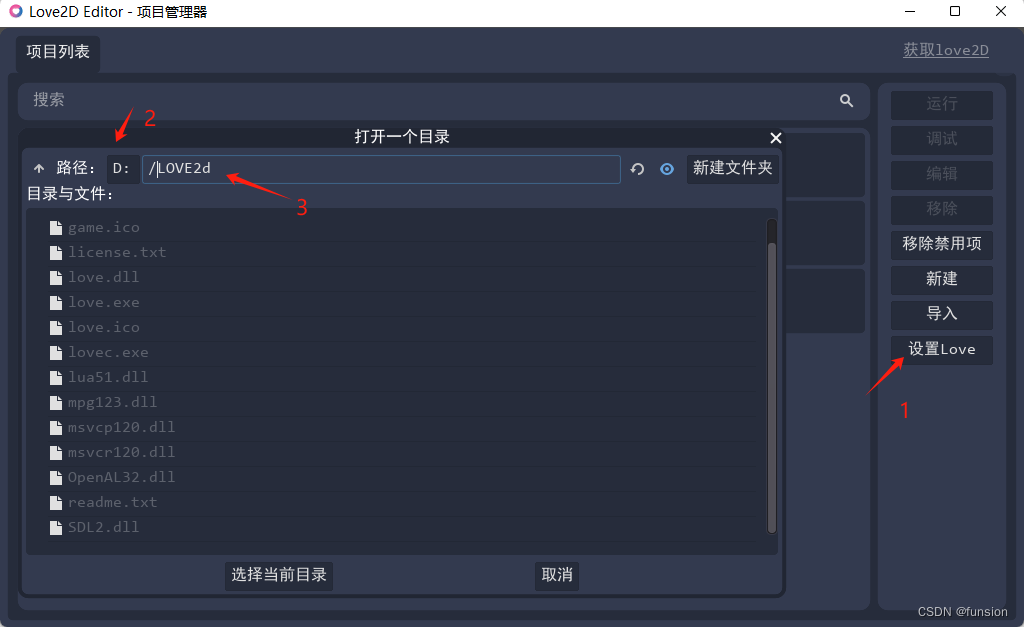
love 2d win 下超简单安装方式,学习Lua 中文编程 刚需!!
一、下载love 2d
参考:【Love2d从青铜到王者】第一篇:Love2d入门以及安装教程 或直接下载: 64位,现在一般电脑都可以用。
64-bit zipped 32位,很复古的电脑都可以用。
32-bit zipped 二、解压
下载好了之后,解压到…
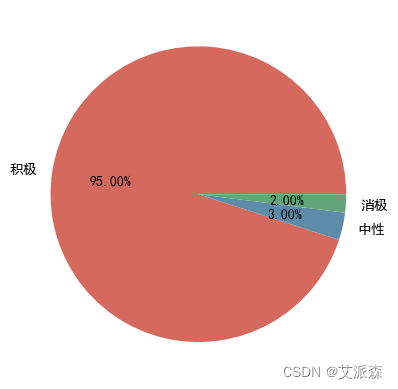
基于Python爬虫+词云图+情感分析对某东上完美日记的用户评论分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…

【自然语言处理】NLP学习及实践记录 | part 01 自然语言实现中文分词|句法分析
项目需要,所以学习一下,自然语言处理,主要是【知识库构建】、【自动摘要生成】、【个性推荐算法】、【聊天机器人|问答系统】这几个部分的应用。
有哪些部分在我们学习NLP过程中提的比较多的呢?这是老师在讲课开始提的一个问题&a…
love 2d Lua 俄罗斯方块超详细教程
源码已经更新在CSDN的码库里:
git clone https://gitcode.com/funsion/love2d-game.git 一直在找Lua 能快速便捷实现图形界面的软件,找了一堆,终于发现love2d是小而美的原生lua图形界面实现的方式。
并参考相关教程做了一个更详细的&#x…

TikTok 购物和直播的 5 个简单技巧
TikTok 的一切都很大:应用程序下载量、受众规模和病毒式营销活动。因此,该公司多方面进军社交商务也就不足为奇了。是的,这将是巨大的。自去年年底以来,TikTok Shopping 和TikTok 直播购物活动已在一些市场上线,并将于…
pyhanlp 文本聚类详细介绍
文本聚类
文本聚类简单点的来说就是将文本视作一个样本,在其上面进行聚类操作。但是与我们机器学习中常用的聚类操作不同之处在于。
我们的聚类对象不是直接的文本本身,而是文本提取出来的特征。因此如何提取特征因而是非常重要的一步。在HanLP中一共有…

中文编程入门(Lua5.4.6中文版)第十一章 Lua 模块与包 参考星争际霸游戏
在遥远的星争际霸世界中,代码模块就如同星际基地中的高科技仓库,储存着各类经过封装优化的战术指令和战略资源。自Lua 5.1版本起,星际编程者们引入了标准化的模块管理系统,使得不同战舰之间能够共享和调用核心战斗算法,…

Java 结合中文分词库 jieba 统计一堆文本中各个词语的出现次数【代码记录】
文章目录 1、需求2、代码3、结果 1、需求 2、代码
package com.zibo.main;import com.huaban.analysis.jieba.JiebaSegmenter;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
imp…
golang实现中文分词,scws,jieba
一、scws
1、安装 scws
官网以及文档 https://github.com/hightman/scws
wget -q -O - http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2 | tar xjf -cd scws-1.2.3
./configure --prefix/usr/local/scws --enable-shared
make && make installLibraries hav…
jieba模块中文分词应用场景案例
jieba 是一个在 Python 中广泛使用的中文分词库。由于其高效、准确和易用,jieba 在自然语言处理领域有着广泛的应用。下面我将通过一个简单的案例来展示 jieba 在中文分词中的应用场景。
案例:文本分类
假设我们有一个简单的文本分类任务,需…
Python 数据分析的敲门砖 jieba模块中文分词
文章目录 文章开篇Jieba简介使用场景jieba的引用jieba常用的方法1.精确模式分词2.搜索引擎模式分词3.添加新词4.调整词频5.提取关键词 应用案例总结 文章开篇 Python的魅力,犹如星河璀璨,无尽无边;人生苦短、我用Python! Jieba简介…

深度解析中文分词器算法(最大正向/逆向匹配)
中文分词算法概述:
1:非基于词典的分词(nlp语义领域) 相当于人工智能领域计算。一般用于机器学习,特定领域等方法,这种在特定领域的分词可以让计算机在现有的规则模型中,
推理如何分词。在某…
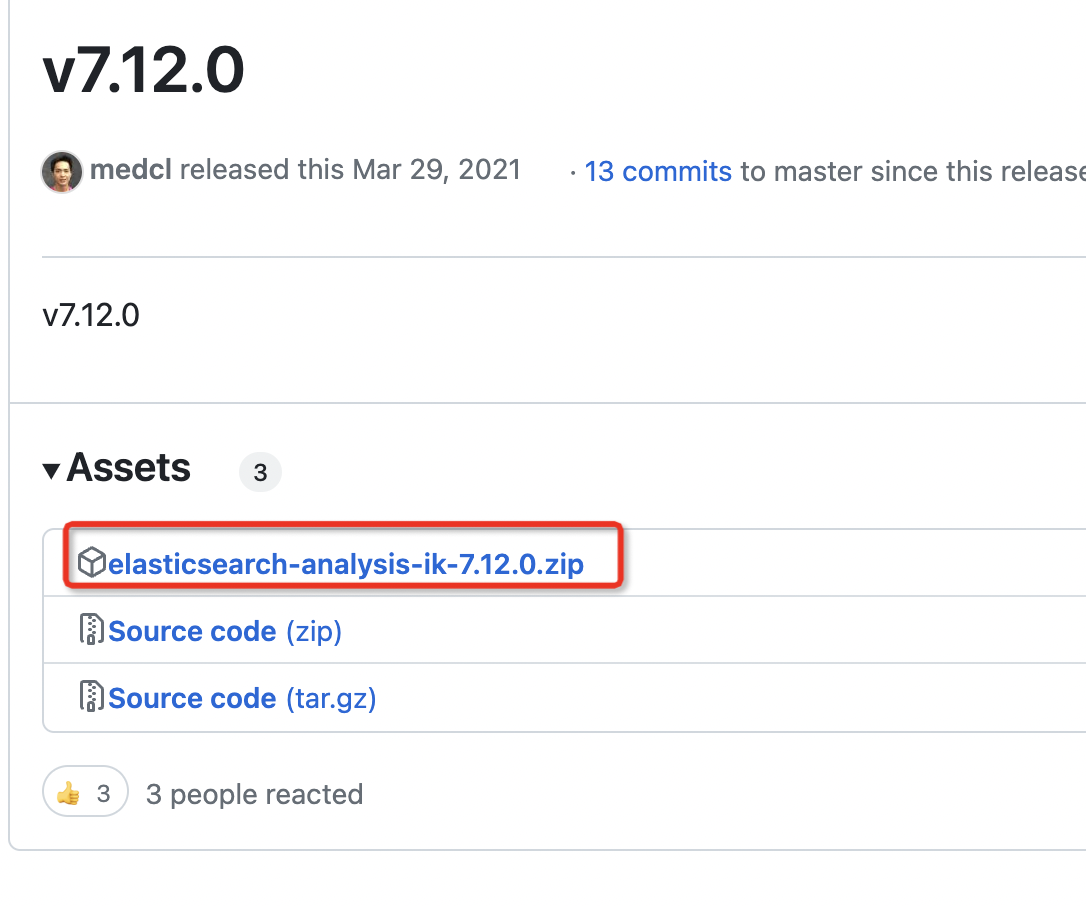
es安装中文分词器 IK
1.下载
https://github.com/medcl/elasticsearch-analysis-ik 这个是官方的下载地址,下载跟自己es版本对应的即可 那么需要下载 7.12.0版本的分词器 2.安装
1.在es的 plugins 的文件夹下先创建一个ik目录 bash cd /home/apps/elasticsearch/plugins/ mkdir ik
…

基于词典的正向最大匹配和逆向最大匹配中文分词
中文分词中基于词典的正向最大匹配和逆向最大匹配
正向最大匹配和逆向最大匹配步骤类似,只是方向不同,我以正向匹配为例,先用一句话去总结它:
在做整个正向成词的过程中,我们做了两个步骤,首先按照字典最…

Elasticsearch分词器-中文分词器ik
文章目录 使用standard analysis对英文进行分词使用standard analysis对中文进行分词安装插件对中文进行友好分词-ik中文分词器下载安装和配置IK分词器使用ik_smart分词器使用ik_max_word分词器 text analysis 使用standard analysis对英文进行分词
ES默认使用standard analys…

ElasticSearch:centos7安装elasticsearch7,kibana,ik中文分词器,云服务器安装elasticsearch
系统:centos7
elasticsearch: 7.17.16
安装目录:/usr/local
云服务器的安全组:开放 9200 和5601的端口 一、下载安装elasticsearch7.17.16
1、安装
#进入安装目录
cd /usr/local#下载elasticsearch
wget https://artifacts.elastic.co/d…
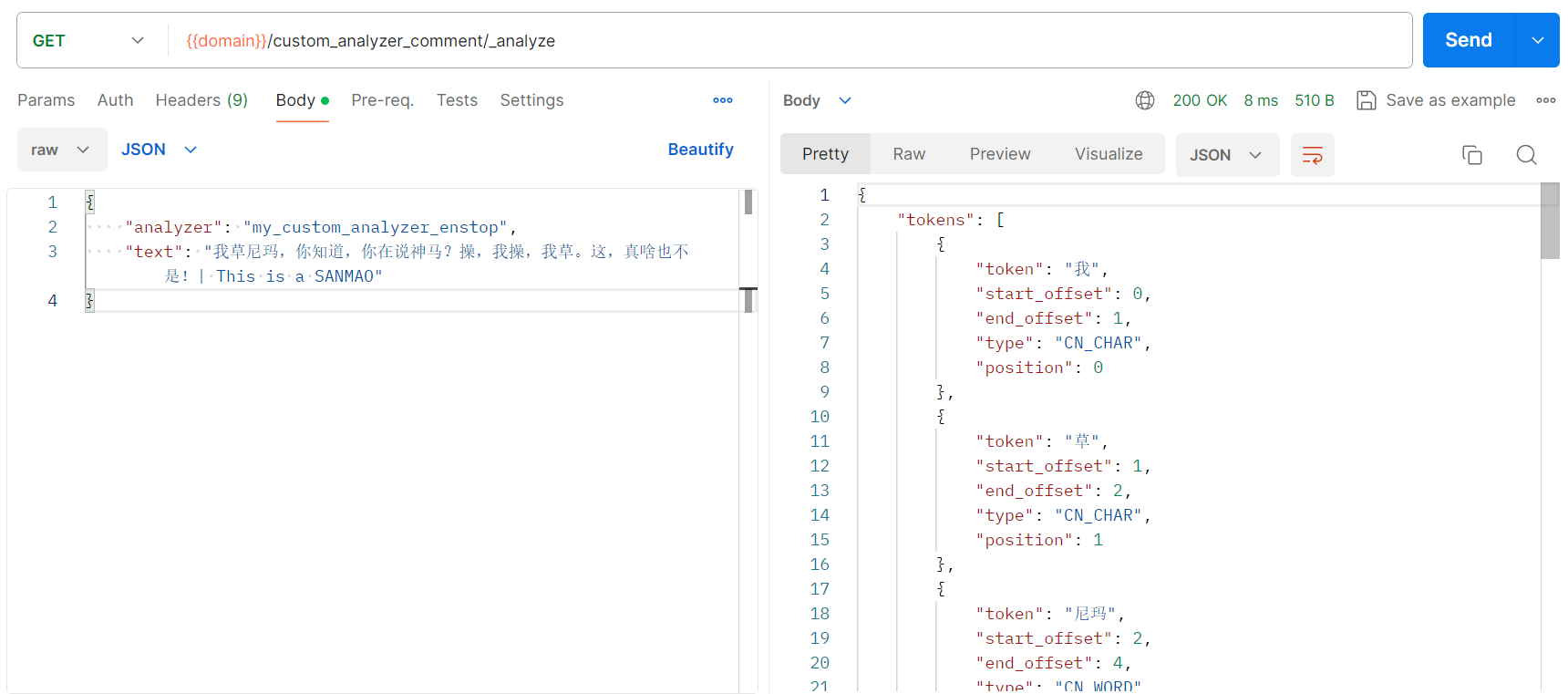
ES6.8.6 为索引映射(Mapping)创建自定义分词器,测试分词匹配效果
文章目录 环境创建索引:配置自定义分词器、字段指定分词器自定义分词器参数说明创建索引:custom_analyzer_comment 使用索引中自定义的分词器进行分词分析自定义分词器my_custom_analyzer分词测试:测试中文停用词、英文字母转小写测试敏感词替…
Python发布API
分为两个文件,一个方法,一个服务。 先看服务文件: import json import translateUtil from flask import Flask, request from flask_cors import CORS
app Flask(__name__) # 实例化 server,把当前这个 python 文件当做一个服…

【Python】jieba分词基础
jieba分词主要有3种模式:
1、精确模式:jieba.cut(文本, cut_allFalse)
2、全模式:jieba.cut(文本, cut_allTrue)
3、搜索引擎模式:jieba.cut_for_search(文本)
分词后的关键词提取:
jieba.analyse.textrank(txt,t…
postgresql中文分词插件安装
1.SCWS 要使用 zhparser,首先需要安装 SCWS 分词库,SCWS 是 Simple Chinese Word Segmentation 的首字母缩写(即:简易中文分词系统)GitHub http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2 ./configure
mak…
华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)
题目描述:
给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。 说明: 1.精确分词: 字符串分词后,不会出现重叠。即“ilovechina” ,不同词库可分割为 “i,love,china” “ilove,c…
Elasticsearch之ik中文分词篇
Elasticsearch之ik中文分词篇 ik分词器插件ik分词器安装ik分词模式es ik分词测试 ik分词器插件
es在7.3版本已经支持中文分词,由于中文分词只能支持到单个字进行分词,不够灵活与适配我们平常使用习惯,所以有很多对应中文分词出现,…

Viterbi算法实现中文分词和词性标注
Viterbi算法目标过程词典分词统计分词词性标注附录附录二附录三源码地址目标
实现基于词典的分词方法和统计分词方法对分词结果进行词性标注对分词及词性标注结果进行评价,包括4个指标:正确率、召回率、F1值和效率
过程
词典分词
基于词典的分词方法…
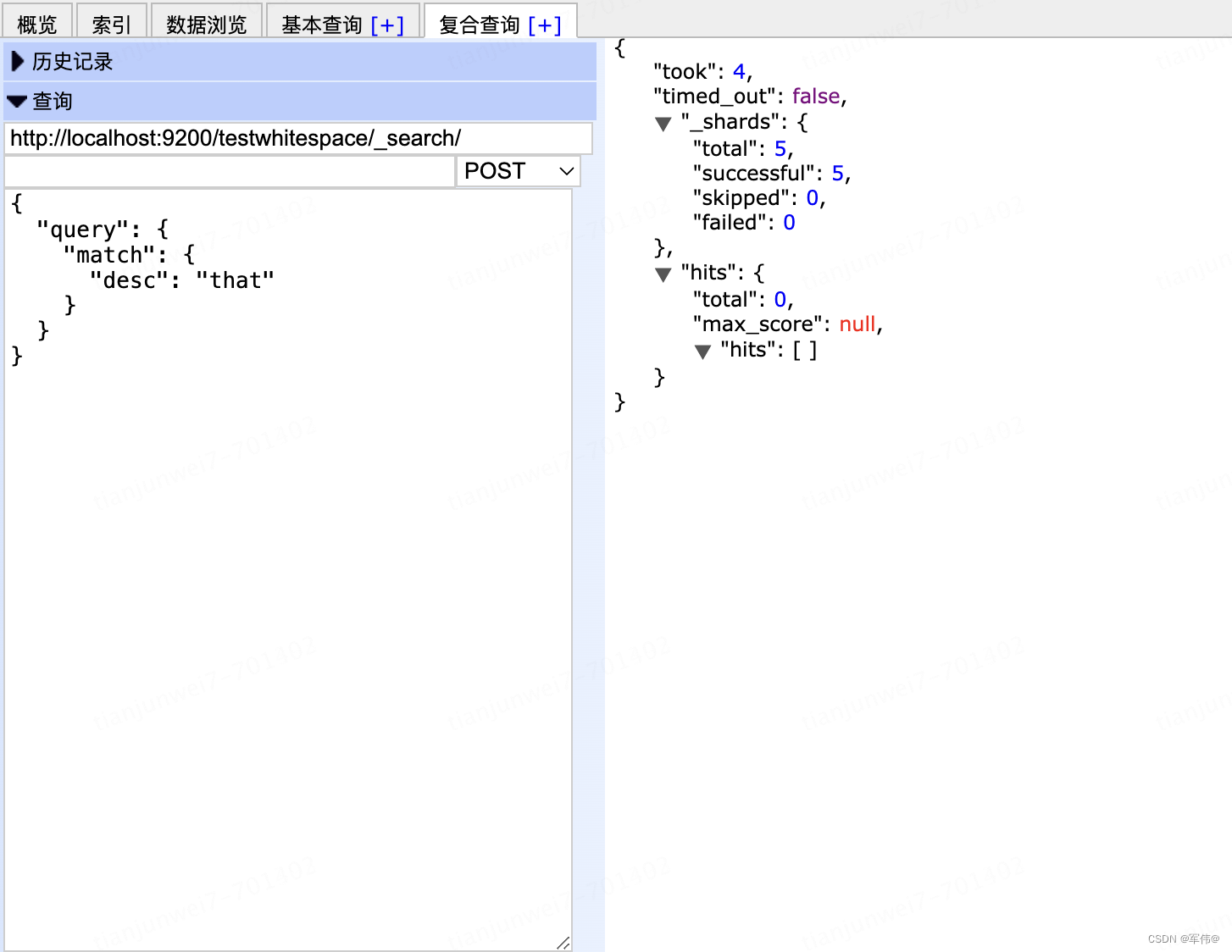
Elasticsearch分词器--空格分词器(whitespace analyzer)
介绍 文本分析,是将全文本转换为一系列单词的过程,也叫分词。analysis是通过analyzer(分词器)来实现的,可以使用Elasticearch内置的分词器,也可以自己去定制一些分词器。除了在数据写入时将词条进行转换,那么在查询的时…
一文了解 StandardTokenizer 分词器,分词原理
一、StandardTokenizer简介
什么是StandardTokenizer?
StandardTokenizer是HanLP中的一个分词器,也是默认的标准分词器。它基于词典和规则的方式对中文文本进行分词,将输入的句子切分成一个个独立的词语。
StandardTokenizer的主要特点如下…
查找替换第2谈:排除```与```之间,文本插入<small>与<small>
提问:
读取 这个new_text
查看有多少个
排除 # 正文\n的行
计算个数# 正文\n)# 正文\n)在偶数与基数的正文中,
例如2-3,4-5中间的正文中,意思是说
排除与之间的代码块分词,计算词性,随机在词语或者短句中间…

炎症回路和肠道微生物
✦ ✦ ✦ 炎症:就是平时人们所说的“发炎”,是机体对于刺激的一种防御反应。炎症,可以是感染引起的感染性炎症,也可以不是由于感染引起的非感染性炎症。 炎症在在各种症状中起重要作用,如脑雾、焦虑和抑郁、腹胀、各种…
HanLP实战教程:离线本地版分词与命名实体识别
HanLP是一个功能强大的自然语言处理库,提供了多种语言的分词、命名实体识别等功能。然而,网上关于HanLP的说明往往比较混乱,很多教程都是针对很多年前的API用法。而HanLP官网主要讲述的是RESTful格式的在线请求,但很少提到离线本地…

随机分词与tokenizer(BPE->BBPE->Wordpiece->Unigram->sentencepiece->bytepiece)
0 tokenizer综述 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。完…
分歧器 friso 的编译和安装测试
Friso 是使用 c 语言开发的一款中文分词器,使用流行的 mmseg 算法实现。完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:MySQL,PHP 等。源码无需修改就能在各种平台下编译使用,加载完 20 万的…

hanlp源码解析之中文分词算法详解
词图
词图指的是句子中所有词可能构成的图。如果一个词A的下一个词可能是B的话,那么A和B之间具有一条路径E(A,B)。一个词可能有多个后续,同时也可能有多个前驱,它们构成的图我称作词图。
需要稀疏2维矩阵模型,以一个词的起始位置…
hanlp中文分词器(ing...)
目前的工作中需要对文本进行分词分析词性,找出热词,经过一系列的调研感觉hanlp这个库还不错,想先试用看看
介绍
HanLP(Han Language Processing)是一个由一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP…
C语言中文分词 Friso的使用教程
Friso是使用C语言开发的一款高性能中文分词器,使用流行的mmseg算法实现。完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:MySQL,PHP等。同时支持对UTF-8/GBK编码的切分。
官方地址:https://…

HanLP vs LTP 分词功能测试
文章摘自github,本次测试选用 HanLP 1.6.0 , LTP 3.4.0
测试思路
使用同一份语料训练两个分词库,同一份测试数据测试两个分词库的性能。 语料库选取1998年01月的人民日报语料库。199801人民日报语料 该词库带有词性标注,为了遵循LTP的训练数据集格式&a…
Hanlp自然语言处理工具之词法分析器
本章是接前两篇《分词工具Hanlp基于感知机的中文分词框架》和《基于结构化感知机的词性标注与命名实体识别框架》的。本系统将同时进行中文分词、词性标注与命名实体识别3个任务的子系统称为“词法分析器”。
加载
对应的类为PerceptronLexicalAnalyzer,其构造方法…

Hanlp等七种优秀的开源中文分词库推荐
中文分词是中文文本处理的基础步骤,也是中文人机自然语言交互的基础模块。由于中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词。
纵观整个开源领域,陆陆续续做中文分词的也有不少,不过目前…
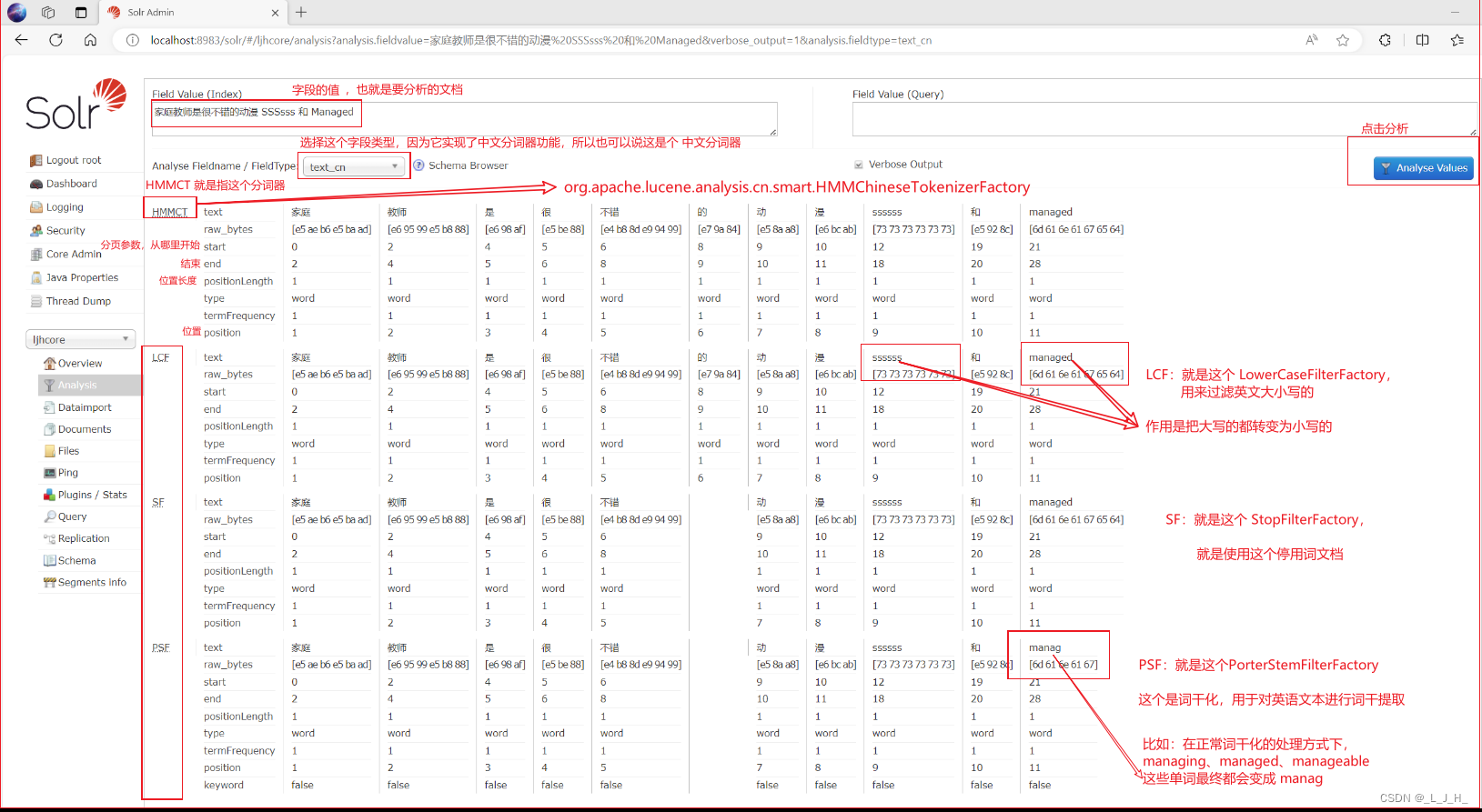
07、全文检索 -- Solr -- Solr 全文检索 之 为索引库添加中文分词器
目录 Solr 全文检索 之 为索引库添加中文分词器添加中文分词器1、添加中文分词器的 jar 包2、修改 managed-schema 配置文件什么是 fieldType 3、添加 停用词文档4、重启 solr5、添加【*_cn】动态字段,并为该字段设置中文分词器6、演示分词器的区别演示 text_cjk 这…

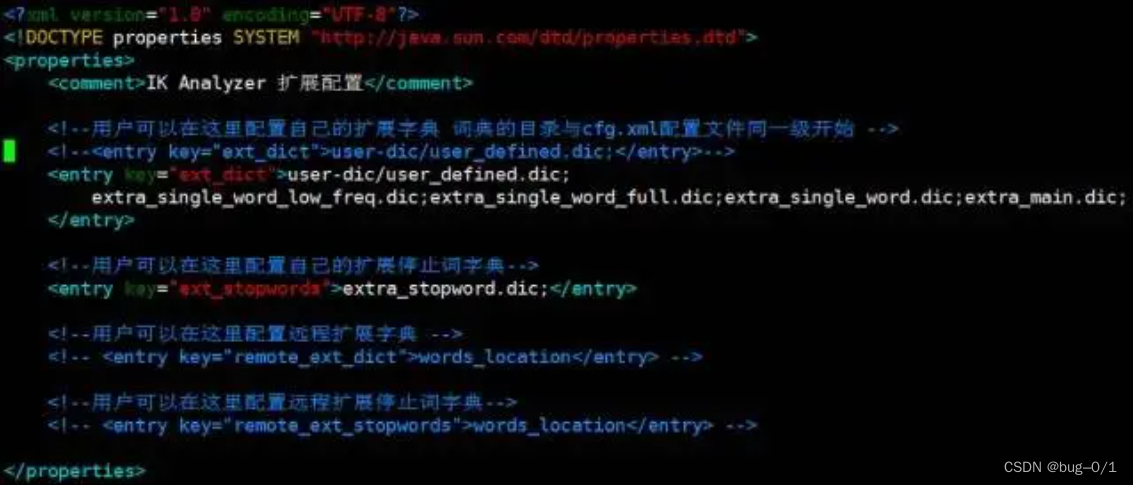
Elasticsearch 全文搜索引擎 ---- IK分词器
原理:分词的原理:二叉树 首先讲一下为什么要出这个文章,前面我们讲过分词方法:中文分词搜索 pscws(感兴趣的同学可以去爬楼看一下),那为什么要讲IK分词?最主要的原因是&…
计算机二级(Python)真题讲解每日一题:《人工智能分词 两问》
在附件中有一个 data.txt文件是一个来源于网上的技术信息资料。…
人工智能Java SDK:词法分析模型能整体性地完成中文分词、词性标注、专名识别任务
文本 - 词法分析SDK [中文]
词法分析模型能整体性地完成中文分词、词性标注、专名识别任务。
词性标注:
n 普通名词f 方位名词s 处所名词t 时间nr 人名ns 地名nt 机构名nw 作品名nz 其他专名v 普通动词vd 动副词vn 名动词a 形容词ad 副形词an 名形词d 副词m 数量…
springcloud-gateway聚合knife4j接口文档
版本选择:
本次swagger接口聚合并非引入swagger依赖,而是使用了knife4j,这个依赖包是对swagger前段页面做了美化,使其更加好看,操作性更强
注意:本次文章中接口文档底层为swagger2
版本选择
组件版本spring-boot2.3.12.RELEAS…

图数据库Neo4J 中文分词查询及全文检索(建立全文索引)
Neo4j的全文索引是基于Lucene实现的,但是Lucene默认情况下只提供了基于英文的分词器,下篇文章我们在讨论中文分词器(IK)的引用,本篇默认基于英文分词来做。我们前边文章就举例说明过,比如我要搜索苹果公司&…
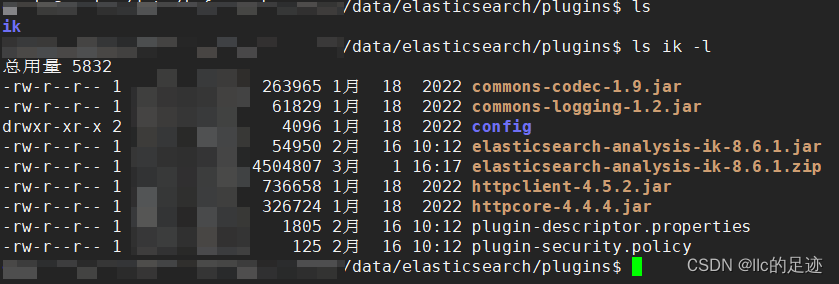
elasticsearch 8 修改分词器并数据迁移
1. 安装中文索引
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意:版本要和ES版本对应 解压后放入plugins文件中 然后重启服务:docker-compose restart elasticsearch,大概需要1分钟
2. 数据迁移…
发布 IK Analyzer 2012 版本
[sizelarge][b]新版本改进:[/b][/size]
[list]
[*]支持分词歧义处理
[*]支持数量词合并
[*]词典支持中英文混合词语,如:Hold住
[/list][sizelarge][b]IK Analyzer 2012特性[/b][/size]
[list]
[*]采用了特有的“正向迭代最细粒度切分算法“&a…
Elasticsearch 8.10之前同义词最佳实践
1、同义词在搜索引擎领域用途
同义词在搜索引擎领域的用途可概括如下: 增强搜索的准确性——当用户输入一个关键词时,可能与他们实际意图相关的文档使用了一个不同的关键词或短语。同义词允许搜索引擎理解和识别这些情况,返回更准确的结果。如:“遥遥领先”和“华为Meta60…
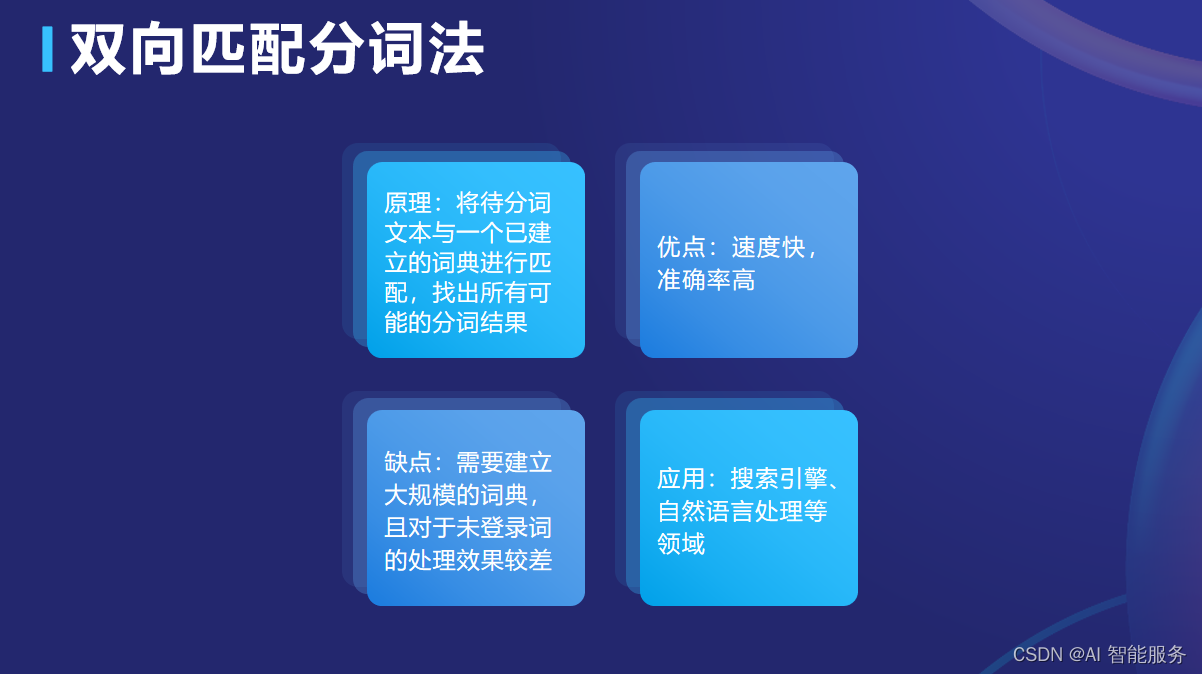
基础课8——中文分词
中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个…
利用Python进行中文分词——实现中文文本处理的基础工具
中文是一种复杂的语言,其词语之间没有明显的分隔符号,这给中文文本处理带来了一定的挑战。为了更好地处理中文文本数据,Python提供了许多优秀的中文分词工具和库。中文分词是将连续的中文文本切分成独立词语的过程,是中文文本处理…
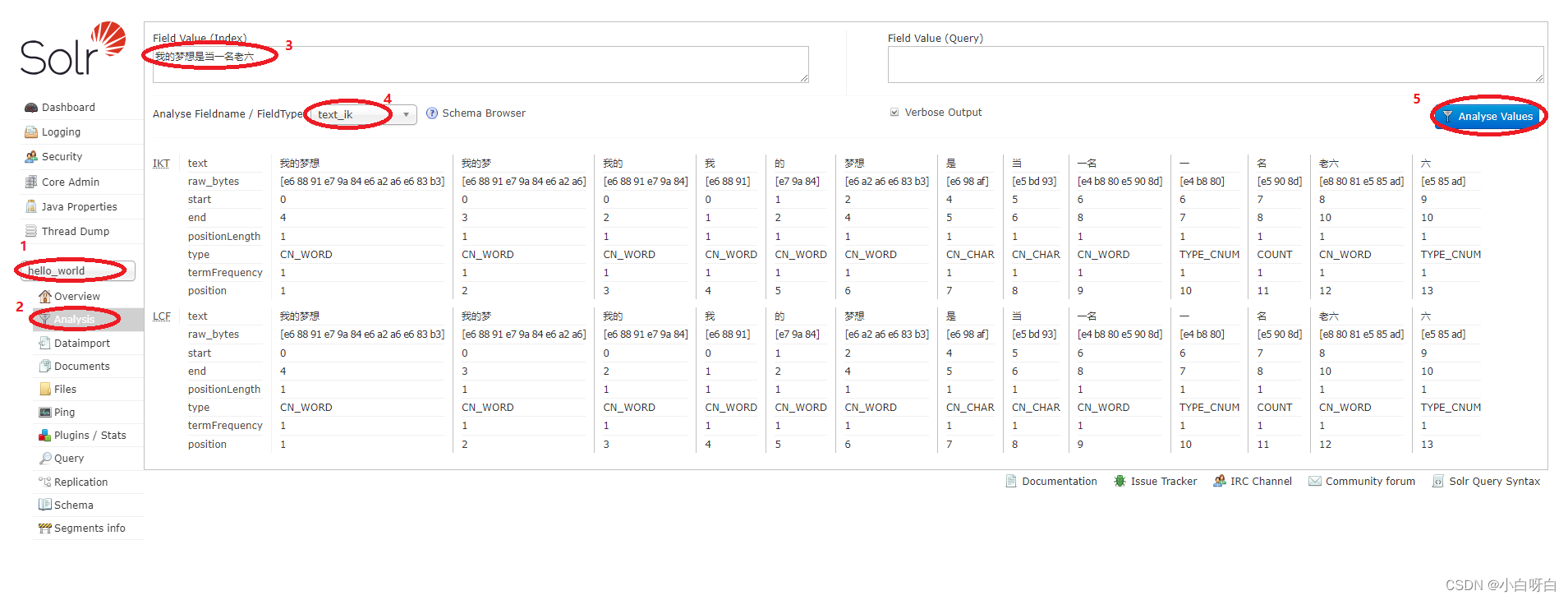
【Solr】中文分词配置
提示:在设置中文分词前需确保已经生成过core,未生成core的可以使用:solr create -c "自定义名称"进行定义。 未分词前的效果预览: 下载分词器: 下载地址: https://mvnrepository.com/artifact/com.github.m…

HanLP中的人名识别分析详解
在看源码之前,先看几遍论文《基于角色标注的中国人名自动识别研究》
关于命名识别的一些问题,可参考下列一些issue:
u名字识别的问题 #387u机构名识别错误u关于层叠HMM中文实体识别的过程
HanLP参考博客:
词性标注
层叠HMM-Viterbi角色标…
中文分词库:jieba的词性对照表
jieba词性对照表
字母词性a形容词ad副形词ag形容词性语素an名形词b区别词c连词d副词dg副词素e叹词f方位词g语素h前接成分i成语j简称略称k后接成分l习用语m数词mq数量词n名词ng名词性语素nr人名ns地名nt机构团体名nz其他专名o拟声词p介词q量词r代词rg代词性语素rr人称代词rz指示…
中文分词库-jieba
问题1:(8分)用 jieba 分词,计算字符串 s 中的中文词汇个数,不包括中文标点符号。显示输出分词后的结果,用”/ ”分隔,以及中文词汇个数。示例如下:
输入:
工业互联网”…

论文:Zero-Shot Entity Linking by Reading Entity Descriptions翻译笔记(阅读实体描述、实体链接)
文章目录 论文题目:通过阅读实体描述实现零样本实体链接摘要1 介绍2 零点实体链接2.1 审查: 实体链接2.2 任务定义2.3 与其他 EL 任务的关系 3 数据集构建4 实体链接模型4.1 生成候选4.2 候选排序 5 适应目标世界6 实验6.1 基线6.2 对未知实体和新世界6.…

比较好的中文分词方案汇总推荐
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块。不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性、句法树等模块的效果…

ElasticSearch实战指南必知必会:安装中文分词器、ES-Python使用、高级查询实现位置坐标搜索以及打分机制
ElasticSearch实战指南必知必会:安装中文分词器、ES-Python使用、高级查询实现位置坐标搜索以及打分机制
1.ElasticSearch之-安装中文分词器
elasticsearch 提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whit…
Elasticsearch+head+Ik中文分词器的安装以及Go操作Elasticsearch
Go操作Elasticsearch
一、elasticsearch是什么
elasticsearch是一个基于Lucene的搜索服务器,采用Java语言编写,使用Lucene构建索引、提供搜索功能,并作为Apache许可条款下的开发源码发布,是当前流行的企业级搜索引擎。其实Lucene的功能已经很强大了,为什么还要多此一举的…

编辑与校对的艺术:如何提高公文写作质量
在写作过程中,编辑与校对是提高作品质量的关键环节。它们不仅涉及语法、拼写和标点等基本问题,还包括文本的组织、表达和内容。通过掌握编辑与校对的艺术,你可以使你的文字更具说服力、更清晰易懂,从而更有效地传达你的观点。 1.认…
发布 IK Analyzer 2012 FF 版本
首先感谢大家对IK分词器的关注。最近一段时间正式公司事务最忙碌的时候,Lucene4.0和Solr4.0发布后,便收到了广大网友的大量邮件要求更新版本,这让我既开心又感到鸭梨大啊~~花了3天时间,了解了Lucene4.0和solr 4.0与分词相关部分的…
中文分词的词典中的词性标记
词性标记: 包含 ICTPOS3.0词性标记集、ICTCLAS 汉语词性标注集、jieba 字典中出现的词性、simhash 中可以忽略的部分词性。
词分类
实词:名词、动词、形容词、状态词、区别词、数词、量词、代词虚词:副词、介词、连词、助词、拟声词、叹词。…

中文分词演进(查词典,hmm标注,无监督统计)新词发现
查词典和字标注 目前中文分词主要有两种思路:查词典和字标注。 首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。 查词典的方法…

人机交互——对话管理
人机交互中的对话管理主要是指在人机交互过程中,对交互的对话内容和流程进行管理,以实现自然、流畅、高效的交互效果。对话管理包括对话状态追踪、对话策略优化等多个方面。
对话状态追踪是指对当前对话的状态进行跟踪,例如对用户输入的语…

人机交互——自然语言理解
人机交互中的自然语言理解是人机交互的核心,它是指用自然语言(例如中文、英文等)进行交流,使计算机能理解和运用人类社会的自然语言,实现人机之间的自然语言通信。
自然语言理解在人工智能领域中有着非常重要的地位&a…
chatgpt赋能python:Python中的中文分词神器——jieba
Python中的中文分词神器——jieba
介绍
如果你曾经在处理中文文本时,也许会遇到中文分词的需求,jieba就是一款不可错过的工具。
jieba 是目前最好的 Python 中文分词库,它具有高效、简单和可定制等优点,适合各种规模的文本分词…
188.【2023年华为OD机试真题(C卷)】中文分词模拟器(字典树动态规划算法—JavaPythonC++JS实现)
请到本专栏顶置查阅最新的华为OD机试宝典 点击跳转到本专栏-算法之翼:华为OD机试 🚀你的旅程将在这里启航!本专栏所有题目均包含优质解题思路,高质量解题代码,详细代码讲解,助你深入学习,深度掌握! 文章目录 188.【2023年华为OD机试真题(C卷)】中文分词模拟器(…
数据分类分级 数据识别-实现部分敏感数据识别
目录 敏感数据识别敏感字段敏感字段识别方式敏感数据识别规则 代码示例正则表达式身份证号手机号座机号邮箱地址Ipv4地址Ipv6地址MAC地址中国新旧版、英、美、日、韩、加拿大护照性别民族省份医师资格证书医师执业证书永久居住证港澳通行证大陆通行证军官证关键字地址算法

Python使用词云图展示
网上看到一个txt文本信息,共2351条饭否记录,据说是微信之父每天发的饭否记录,其实我不知道什么是饭否。我读取这个文本内容,展示到词语图上。之前也使用过,但是好久没有玩Python了,称假期空闲,练…
MySQL中文全文检索
MySQL中文全文检索 1.简介:
常规数据库搜索都是用 like 语句,但是like 语句是不能利用索引的,查询效率极其低下。这也就是为什么很多功能都只提供标题搜索的原因,因为如果搜索内容,几万数据就跑不动了。
Mysql 全文索…

人机交互——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。
1.简介
自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…

中文分词和tfidf特征应用
文章目录 引言1. NLP 的基础任务 --分词2. 中文分词2.1 中文分词-难点2.2 中文分词-正向最大匹配2.2.1 实现方式一2.2.2 实现方式二 利用前缀字典 2.3 中文分词-反向最大匹配2.4 中文分词-双向最大匹配2.5 中文分词-jieba分词2.5.1 基本用法2.5.2 分词模式2.5.3 其他功能 2.6 三…
Lucene4.3开发之第四步之脱胎换骨(四)
[b][sizex-large]为防止,一些小网站私自盗用原文,请支持原创[/size][/b][b][sizex-large]原文永久链接:[url]http://qindongliang1922.iteye.com/blog/1922742[/url][/size][/b][b][colorgreen][sizex-large]前面几章笔者把Lucene基本入门的任督二脉给打…
NLP基础——中文分词
简介
分词是自然语言处理(NLP)中的一个基本任务,它涉及将连续的文本序列切分成多个有意义的单元,这些单元通常被称为“词”或“tokens”。在英语等使用空格作为自然分隔符的语言中,分词相对简单,因为大部分…

【MySQL8】中文分词支持全文索引
第一步:
配置文件my.ini(Windows 10默认路径: C:\ProgramData\MySQL\MySQL Server 8.0) 中增加如下配置项,同时重启MySQL80 服务: [mysqld] ngram_token_size2 #这句话可以使中文按2个文字切词,进行全文索引 第…

【Python 词云】无聊的时候就来动手制作一个属于自己的词云吧
前言: 没接触Python就感觉词云还挺好玩的,所以现在刚学完词云制作就来和大家分享一波,英文词云制作比较简单,所以在这里直接分享中文词云制作方法,完整代码放在最后自取。 一、效果展示
制作步骤 1.先导入我们所需要…

如何使用 TikTok 提高亚马逊销量
TikTok(及其受众)比以往任何时候都更大。爱它或恨它,它的影响力都难以忽视。
作为2021 年下载量第一的应用程序,拥有超过 10 亿用户,TikTok 对于希望直接与客户建立联系的品牌来说已经变得至关重要。循环、无限滚动和…

简易搜索引擎SEWeibo
背景
有一组微博事件数据,之前做了一些数据分析与挖掘的工作。想着用C做一个简单的搜索引擎玩玩。
亮点:
搜索支持关系关键字作为搜索条件,以文本情感极性作为初筛条件,以TF-IDF为搜索排序依据以Reactor模式为基础,…
基于Docker安装Elasticsearch【保姆级教程、内含图解】
Elasticsearch官网:欢迎来到 Elastic — Elasticsearch 和 Kibana 的开发者 | Elastic 学习任何框架和技术,一定要参考相应的官网学习,一定要参考官网学习!!! 注意:Elasticsearch官网访问和加载…

【Python机器学习】条件随机场模型CRF及在中文分词中实战(附源码和数据集)
需要源码请点赞关注收藏后评论区留言私信~~~ 基本思想
假如有另一个标注序列(代词 动词 名词 动词 动词),如何来评价哪个序列更合理呢?
条件随机场的做法是给两个序列“打分”,得分高的序列被认为是更合理的。既然要…

使用jieba库进行中文分词和去除停用词
jieba.lcut
jieba.lcut()和jieba.lcut_for_search()是jieba库中的两个分词函数,它们的功能和参数略有不同。
jieba.lcut()方法接受三个参数:需要分词的字符串,是否使用全模式(默认为False)以及是否使用HMM模型&…