代码规范
阿克曼
语音识别
人脸识别
弹性布局
OTA
kinect
产品运营
gerapy
基础入门
美食分享系统
Cartographer
上位机
文档管理
抓包
tee
图形化编程
企业人事管理系统
database
地图随机点
ASR
2024/4/11 22:19:04
语音识别笔记 (六) 多遍解码、三音子模型
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本讲我们来简要讨论一些语音识别的高级话题,包含多遍解码和三音子模型。 第六讲
多通道解码(Multi-pass Decoding)
在上一讲中,我们介绍了基于Viterbi算法的解…

语音识别笔记(一)简介与高斯混合模型
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 黄学东老师那本太厚了。。。自己根据需要先四处搜集学习吧~ 第一章 简介
自动语音识别(Automatic speech recongnition, ASR)技术时使人与人。人与机器交流的关…

Windows Defense Mechanism - Part 1
Overview
If I’m a long-time CTF player (or HackTheBox lab machine player), things are gonna go a little off when I’m put into a real world scenario - meaning that, when facing a well defended Windows machine.
This article will summarize the main Window…

语音识别笔记(二)计算音系学
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 研究词是如何通过音子(phone)的单个语言单位发出声音的。 第三讲
基于语音的文字系统表明,口语词是由言语的最小单位组合而成的,这是作为我们所有的现代音系学理…
语音识别笔记 (五) MFCC,搜索-解码,Embedded Training
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 讲完声学模型的建立,现在我们就来讲讲它的输入和输出应该怎么处理. 第五讲
梅尔频率倒谱系数(MFCC)
在一个ASR系统中,第一步要做的就是特征提取.从前面的计算音系学部分可知,声音的音…
ASR工业化语音模型总结
1、wenet模型:WeNet语音识别实战-CSDN博客 git地址:GitHub - wenet-e2e/wenet: Production First and Production Ready End-to-End Speech Recognition Toolkit 生产应用方式为:使用pytorch训练,使用c部署。
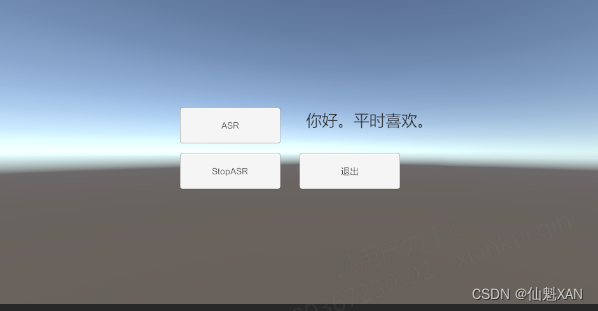
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理 目录
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理
一、简单介绍
二、实现原理
三、注意实现
四、实现步骤 五、关键脚本 一、简单介绍
Unity 工具类,自己整理的一些游戏开发可能用到的模块&#x…

提高广播新闻自动语音识别模型的准确性
语音识别技术的存在让机器能够听懂人类的语言,让机器理解人类的语言。语音识别技术发展至今,已经应运而上了各种各样的语音智能助手,可能有一天我们身边的物体都能和我们说话,万物相连的时代也如期而至。
数据从何而来࿱…
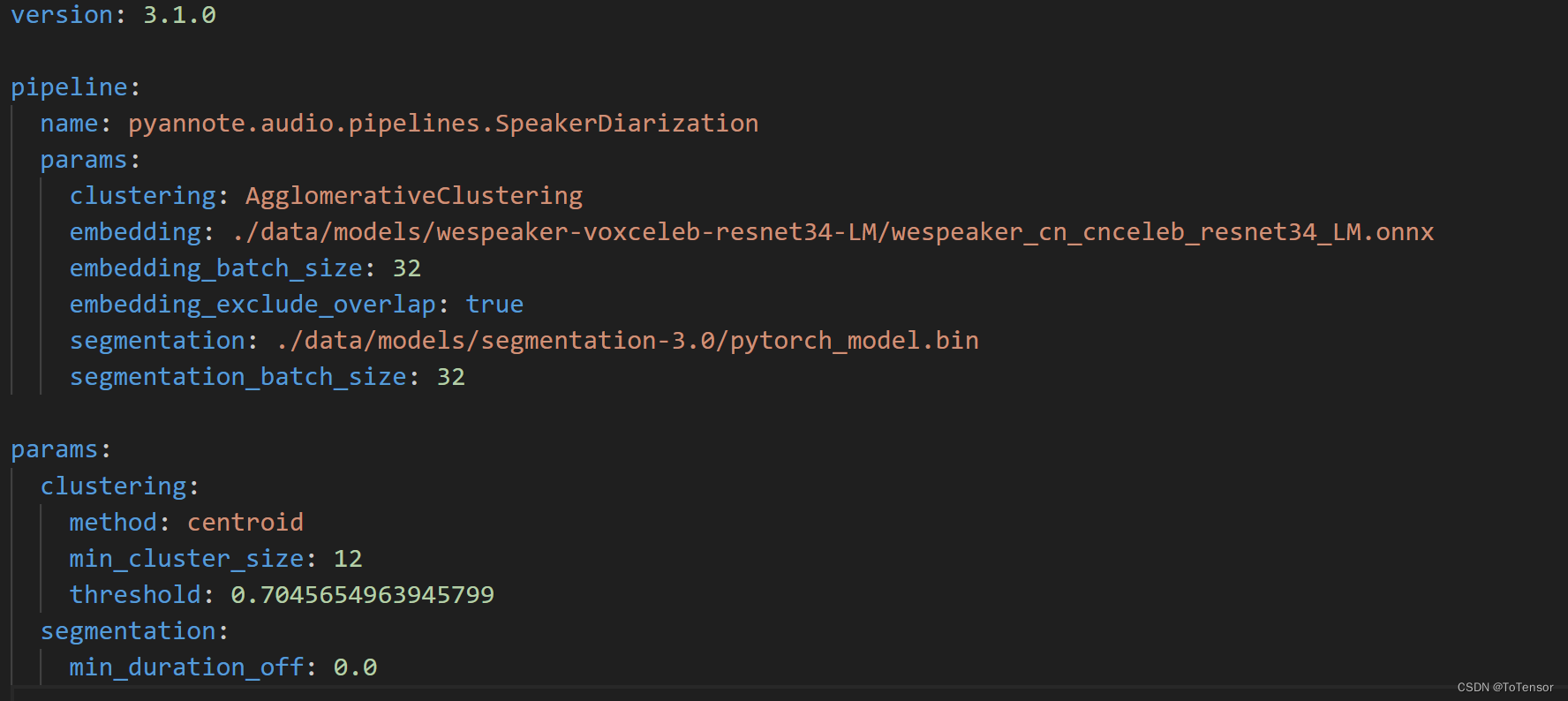
Fastwhisper + Pyannote 实现 ASR + 说话者识别
文章目录 前言一、faster-whisper简单介绍二、pyannote.audio介绍三、faster-whisper pyannote.audio 实现语者识别四、多说几句 前言
最近在研究ASR相关的业务,也是调研了不少模型,踩了不少坑,ASR这块,目前中文普通话效果最好的…
Linux安装Whisper-Jax
博客 如需私有化部署欢迎咨询,包含whisper,whisper jax,faster whisper。
一、前提条件
ubuntu 20.04
python 3.9
cuda 11.8
nvidia-cublas-cu11 11.11.3.6
nvidia-cuda-cupti-cu11 11.8.87
nvidia-cuda-nvcc-cu11 11.8.89
nvidia-cuda-nvrtc-cu11 1…
开源语音识别faster-whisper部署教程
1. 资源下载
源码地址
模型下载地址:
large-v3模型:https://huggingface.co/Systran/faster-whisper-large-v3/tree/main
large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
large-v2模型:…
语音识别笔记(三) 隐马尔科夫模型-HMM
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ HMM作为一种典型的生成模型,在各个领域被广泛应用。我之前一直以为在NLP的序列标注任务中已经完全被CRF取代了,但最近的学习才发现它惊人的生命力。 第三讲
个人…

语音识别笔记 (四) 基于GMM-HMM的自动语音识别框架
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 尽管基于GMM-HMM的语音识别模型已基本被神经网络所取代,但其背后的思想和处理方式仍需要我们仔细学习。 第四讲
自动语音识别(automaic speech recognition)就是建立一个将…

Kaldi thchs30手札(一)特征提取阶段(line 0-33)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ Kaldi是一个语音识别工具包,基于C并遵循Apache v2.0协议。它包含语音信号处理、声学模型训练、解码等一系列工具,同时内部还带有各种语言的源代码实例。非常强大…

Kaldi thchs30手札(二)word-graph(line 38-60)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 38-60行研究和知识总结,重点是word-graph的建立。 概览
先把代码放在这里:
#prepare language stuff
#build a…

Kaldi thchs30手札(三)单音素模型训练(line 62-68)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 62-68行研究和知识总结,内容为单音素模型的训练与解码。 概览
先把代码放在这里:
#monophone
steps/train_…

Kaldi thchs30手札(四)三音子模型(line 71-76)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 71-76 行研究和知识总结,内容为三音子模型的训练与解码测试 概览
首先放代码:
<code class"hljs live…

Kaldi thchs30手札(五)LDA与MLLT(line 78-85)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 78-85 行研究和知识总结,内容涵盖LDA和MLLT部分。 概览
首先放代码:
#lda_mllt
steps/train_lda_mllt.sh --cm…
Kaldi thchs30手札(六)说话人自适应训练(SAT)、FMLLR以及quick训练(line 87-104)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 87-104 行研究和知识总结,内容涵盖说话人自适应训练(Speaker Adaptive Training,SAT)以及特征空间最大似然线性回…

Kaldi thchs30手札(七) DNN-HMM模型的训练
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 106-107 行研究和知识总结,主要内容为Kaldi中nnet1的DNN-HMM模型训练。 概览
首先放代码:
#train dnn model …

Kaldi thchs30手札(八)DAE与TDNN(line 109-115)
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里~ 本部分是对Kaldi thchs30 中run.sh的代码的line 109-115 行研究和知识总结,主要内容为带噪声的神经网络模型以及TDNN的训练。 概览
首先放代码:
#train dae mo…

什么是自动语音识别?
在人工智能发展和全球疫情的双重作用下,企业加强了与客户的线上沟通。企业越发依赖于虚拟助手、聊天机器人以及其他的语音技术,以实现与客户的高效互动。这几类人工智能,都是依赖于自动语音识别技术,简称为ASR。ASR涉及到将语音转…

【超简单】基于PaddleSpeech搭建个人语音听写服务
一、【超简单】之基于PaddleSpeech搭建个人语音听写服务
1.需求分析 亲们,你们要写会议纪要嘛?亲们,你们要写会议纪要嘛?亲们,你们要写会议纪要嘛?当您面对成吨的会议录音,着急写会议纪要而不得不愚公移山、人海战术?听的头晕眼花,听的漏洞百出,听的怀疑人生,那么你…
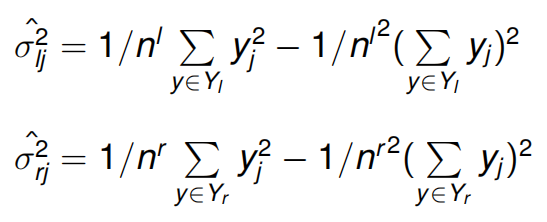
【语音识别】声学建模中基于树的状态绑定
01 基本想法
单音素HMM模型不能很好的应对自然说话人发音时的渐变过程,比如从一个音素转换到另一个音素时会存在协同发音现象。因此语音识别的先驱者提出了上下文建模概念,即使用中心音素(单因素)和前后两个音素组成三音素对每一…

使用openai-whisper 语音转文字
前言:最近由于ChatGPT 的大热,AI 应用领域再次进入大众的视线,今天介绍一款AI应用whisper 可以较为准确的将人声转换为文字(支持多国语言)一、安装安装有两种方式pip 和源码编译安装,这里介绍pip安装方式安…
NeMo中文/英文ASR模型微调训练实践
1.安装nemo
pip install -U nemo_toolkit[all] ASR-metrics
2.下载ASR预训练模型到本地(建议使用huggleface,比nvidia官网快很多)
3.从本地创建ASR模型
asr_model = nemo_asr.models.EncDecCTCModel.restore_from("stt_zh_quartznet15x5.nemo")
3.定义train_m…
ali sdm docker
当然要先安装docker和docker-compose
cd /usr/local
mkdir sdm
cd sdm
touch docker-compose.yml,编辑内容如下:
version: "3"
services:sdm:image: registry.cn-shanghai.aliyuncs.com/nls-cloud/sdm:latestcontainer_name: nls-cloud-s…