如果你通过博客或新闻关注 Elastic,你已经知道在最新版本的 Elasticsearch 中已经提供了用于自然语言处理 (NLP) 的资源。事实上,在我之前的博客文章中,我已经推出了很多关于 NLP 的博文。请详细阅读 “Elastic:开发者上手指南” 中的 “NLP - 自然语言处理” 部分。在今天的练习中,我们将进一步使用一个例子来展示如何使用一个情感分析器来识别情绪。我们可以针对用户的反馈进行统计:positive,nagative 或者 neutral。
满意度调查
在满意度调查中,我们有如下的 4 个问题:
1)How do you rate the customer service provided by the company?
答案有四个:Very good, Good, Bad, Too bad
2)The information about the product/service was passed on clearly and correctly?
答案有两个:A: Yes, Not
3)How would you describe our product(s)/service(s)?
答案有八个:Reliable, Very expensive, Cheap and good, Very qualified, Useful, Little qualified, is not reliable, Ineffective
4)How satisfied are you with our company?
答案有五个:Very satisfied, Satisfied, not very satisfied, Dissatisfied, Very unsatisfied,
模型
我们将使用 DistilBERT base uncased finetuned SST-2 模型。这个也是在之前文章 “Elasticsearch:如何部署 NLP:情绪分析示例” 中所使用的模型。这个模型,我们可以在地址 distilbert-base-uncased-finetuned-sst-2-english · Hugging Face 找到。在网站站中,我们可以看到如下的一个例子:
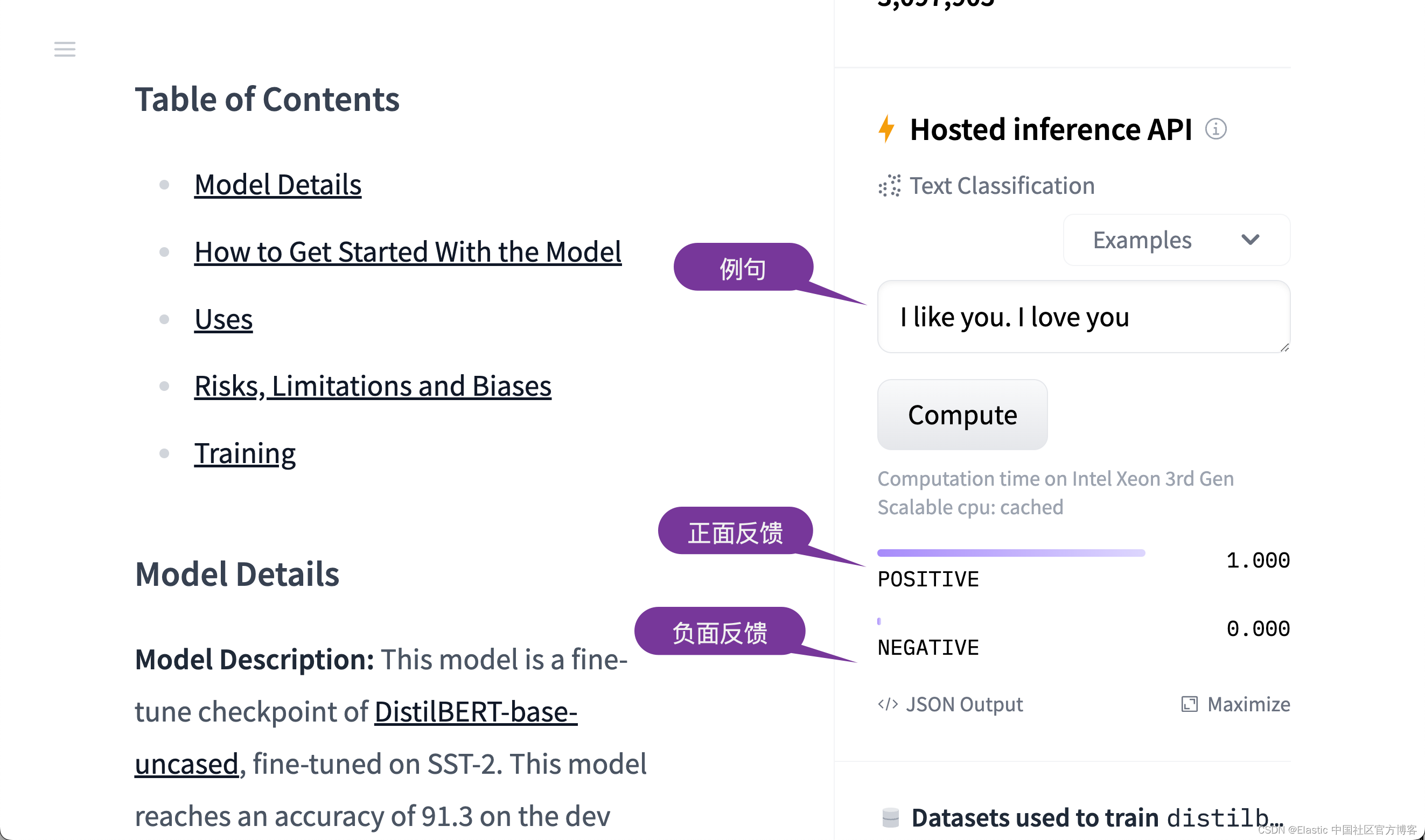
从上面的例子中,我们可以看出来。给定一个句子,它可以帮我们进行情绪判断:正面或者负面。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,我们可以按照如下的方式来安装一个没有安全的 Elasticsearch 集群:
docker-compose.yml
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.6.2
container_name: elasticsearch-8.6.2
environment:
- node.name=elasticsearch
- xpack.security.enabled=false
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
container_name: kibana-8.6.2
restart: always
environment:
ELASTICSEARCH_URL: "http://elasticsearch:9200"
ports:
- 5601:5601
depends_on:
- elasticsearch
volumes:
esdata1:
driver: local我们使用如下的命令来启动:
docker-compose upfrom elasticsearch import Elasticsearch
from pathlib import Path
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
def get_client_es():
return Elasticsearch(
hosts=[{'scheme': 'http', 'host': 'localhost', 'port': 9200}],
request_timeout=300,
verify_certs=False
)
if __name__ == '__main__':
tm = TransformerModel("distilbert-base-uncased-finetuned-sst-2-english", "text_classification")
tmp_path = "models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)
ptm = PyTorchModel(get_client_es(), tm.elasticsearch_model_id())
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config)等上述的命令完成后,我们的 Elasticsearch 将可以在地址 http://localhost:9200 进行访问。 我们可以在 http://localhost:5601 访问 Kibana。
上传模型
我们在本地创建如下的 Python 代码及 requirements.txt 文件:
requirements.txt
elasticsearch~=8.6.2
path
eland~=8.3.0
torch==1.11
transformers
sentence-transformers>=2.1.0main.py
from elasticsearch import Elasticsearch
from pathlib import Path
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
def get_client_es():
return Elasticsearch(
hosts=[{'scheme': 'http', 'host': 'localhost', 'port': 9200}],
request_timeout=300,
verify_certs=False
)
if __name__ == '__main__':
tm = TransformerModel("distilbert-base-uncased-finetuned-sst-2-english", "text_classification")
tmp_path = "models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)
ptm = PyTorchModel(get_client_es(), tm.elasticsearch_model_id())
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config)我们按照如下步骤来运行:
pip3 install -r requirements.txt
我们接下来按照如下的命令来上传模型:
python main.py 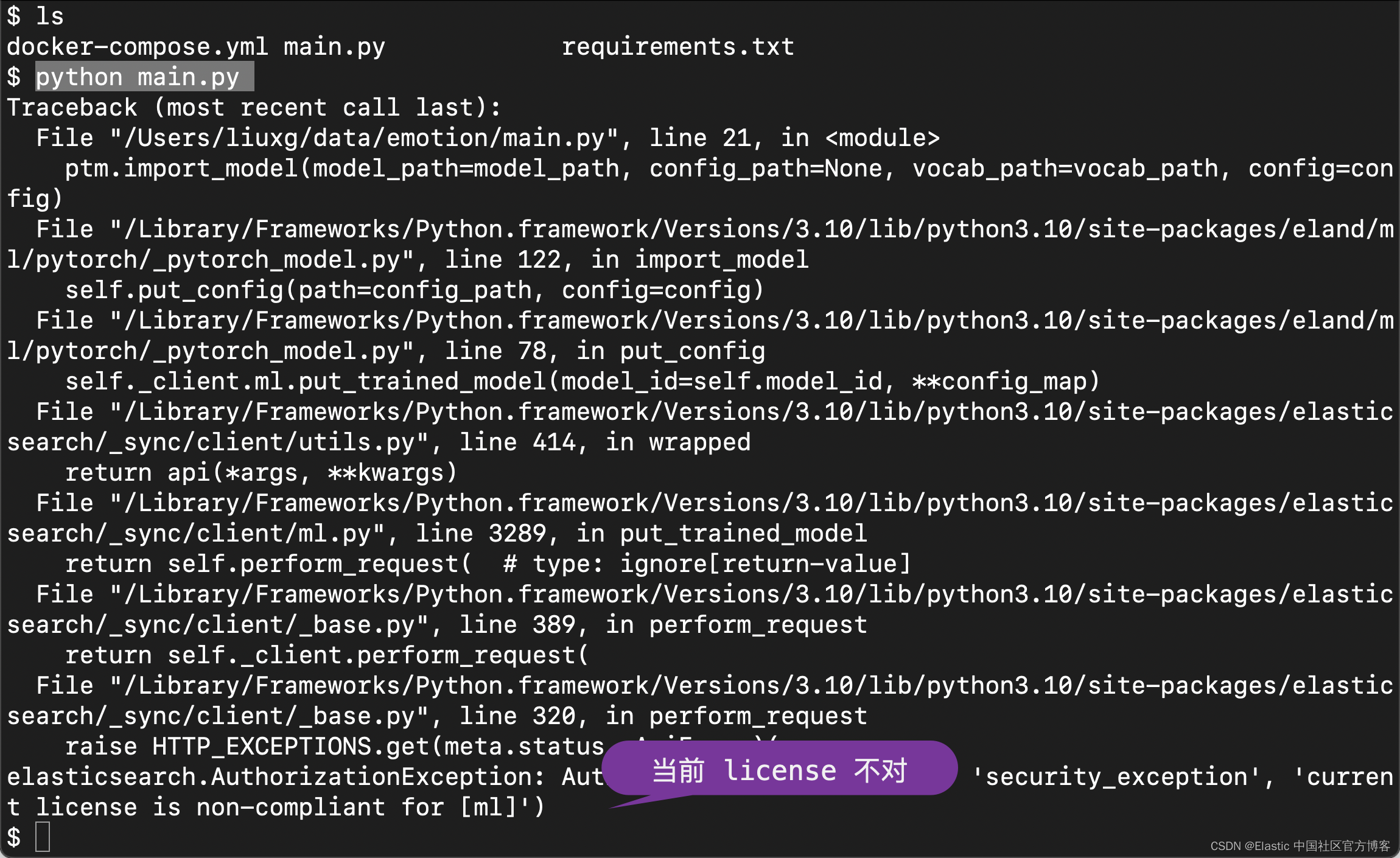
从上面的输出中,我们可以看出来当前的 License 是不对的。我们需要按照如下的方式来启动白金版试用:
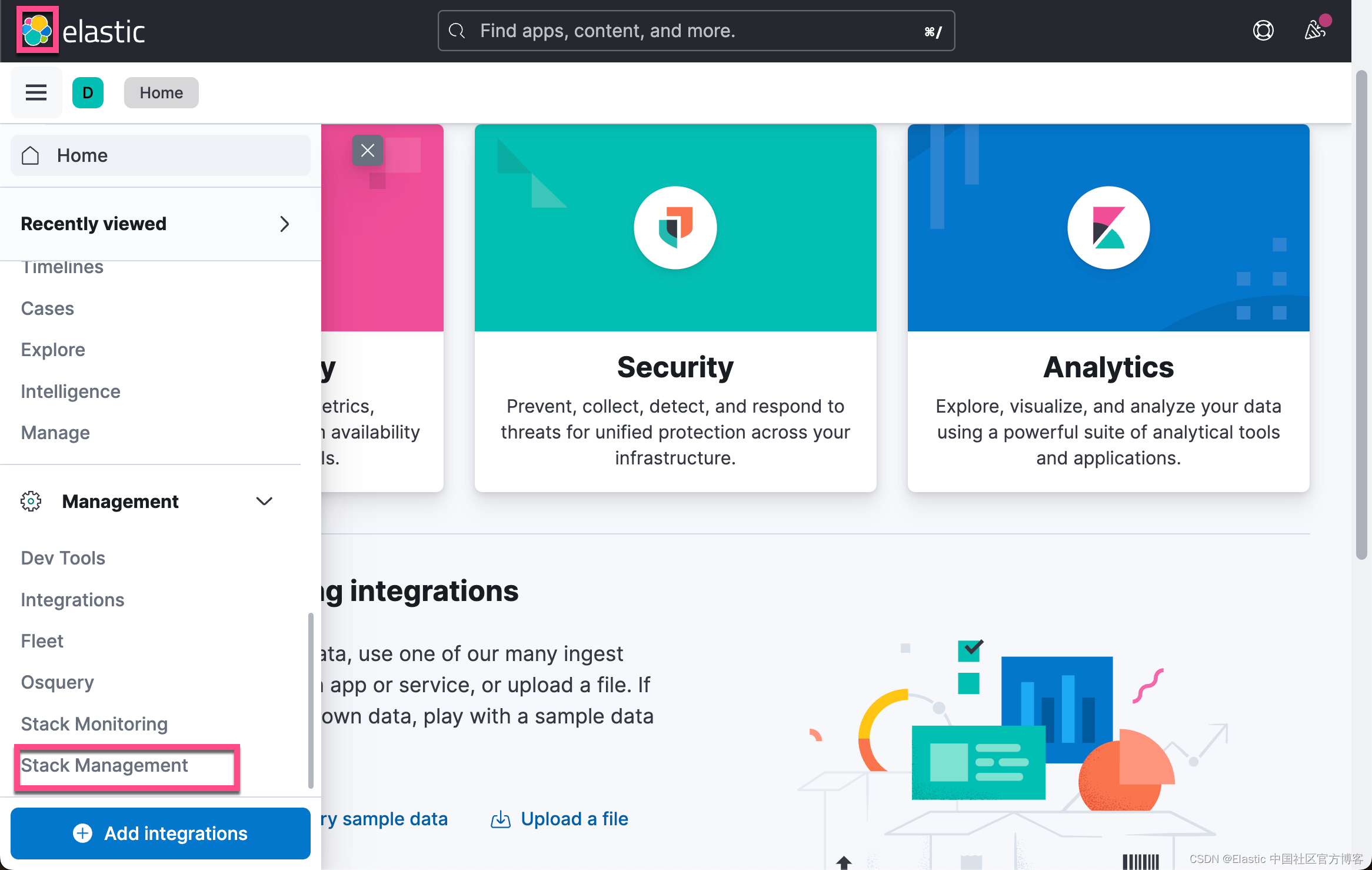
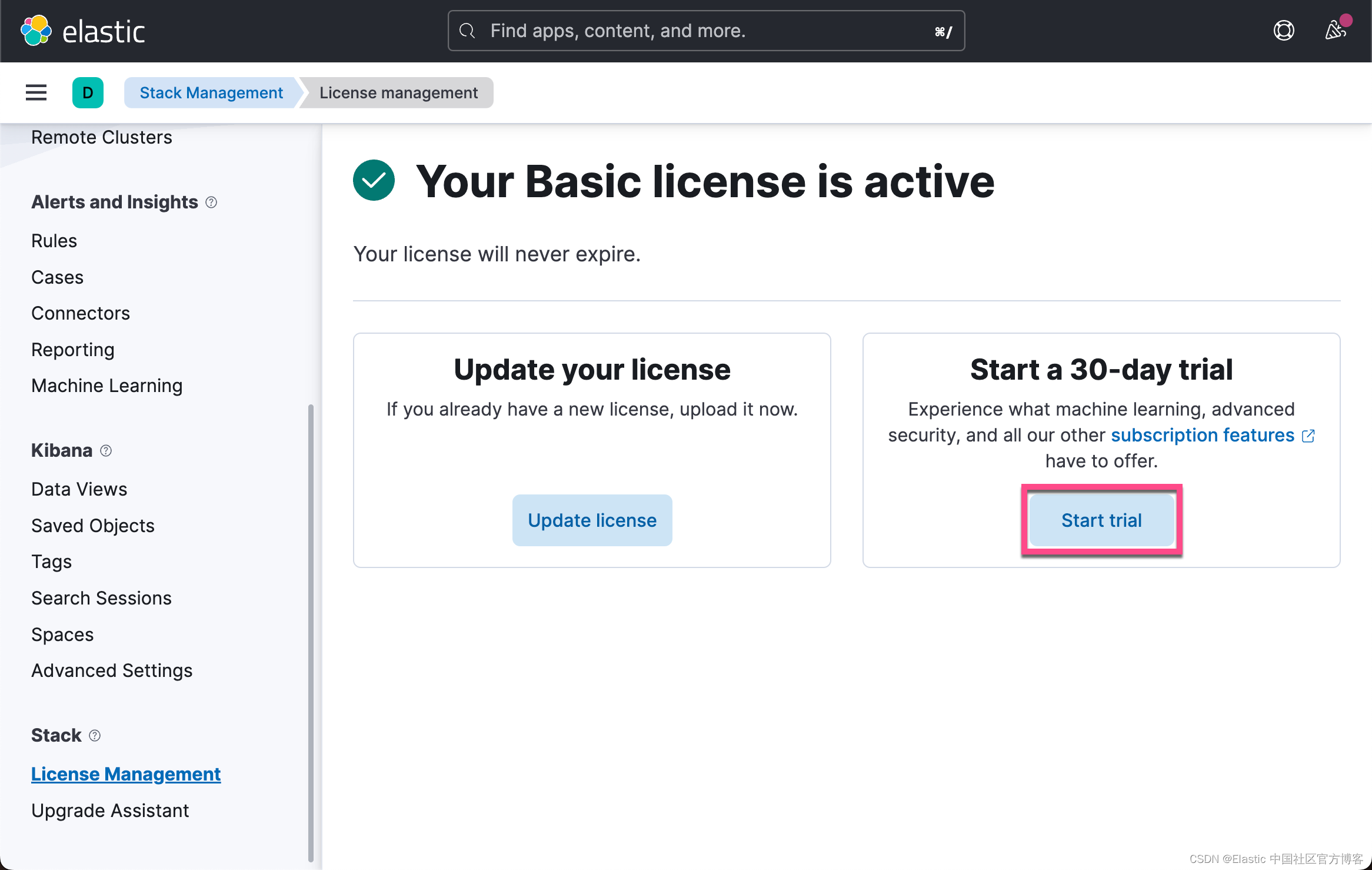
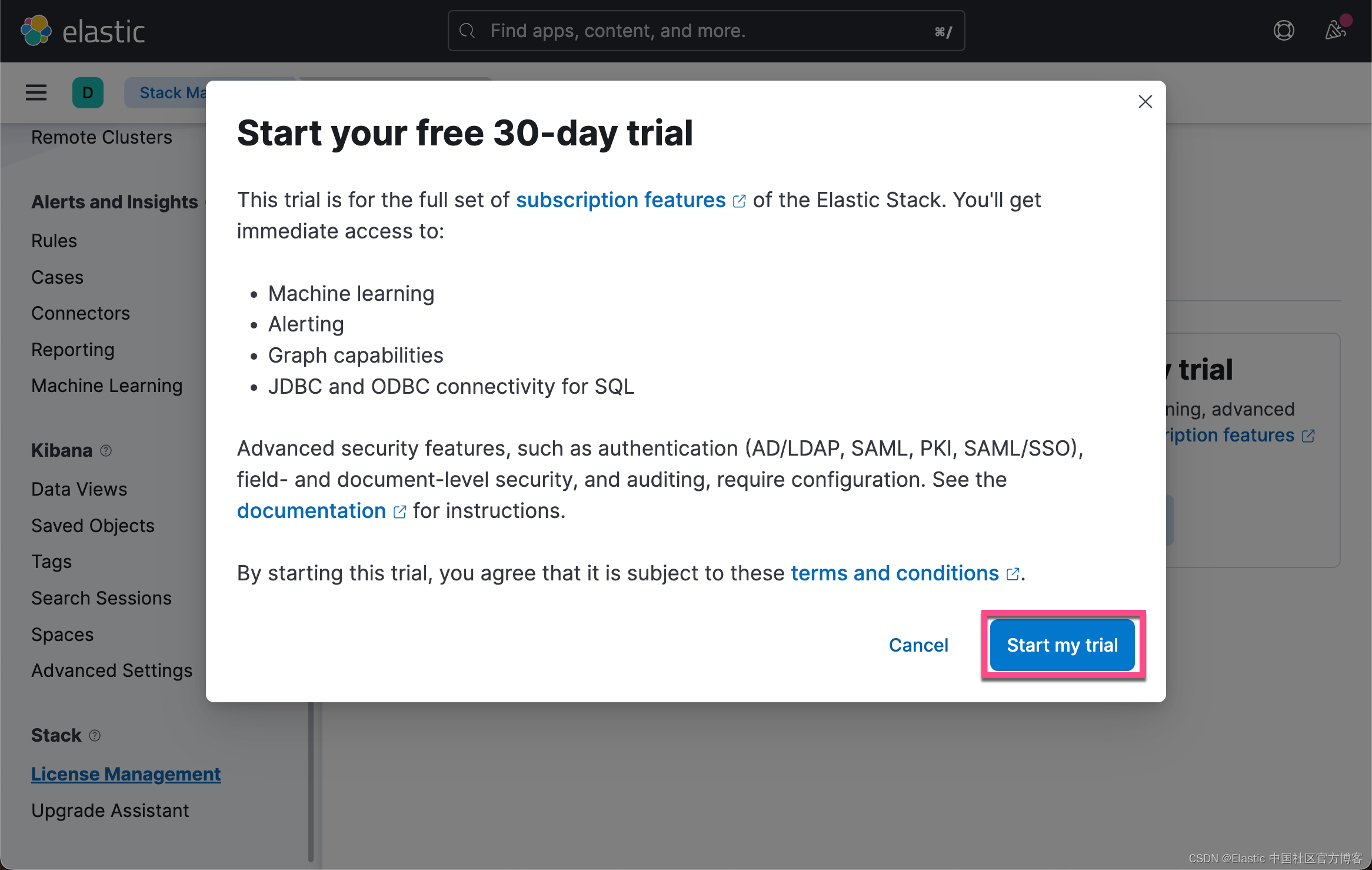
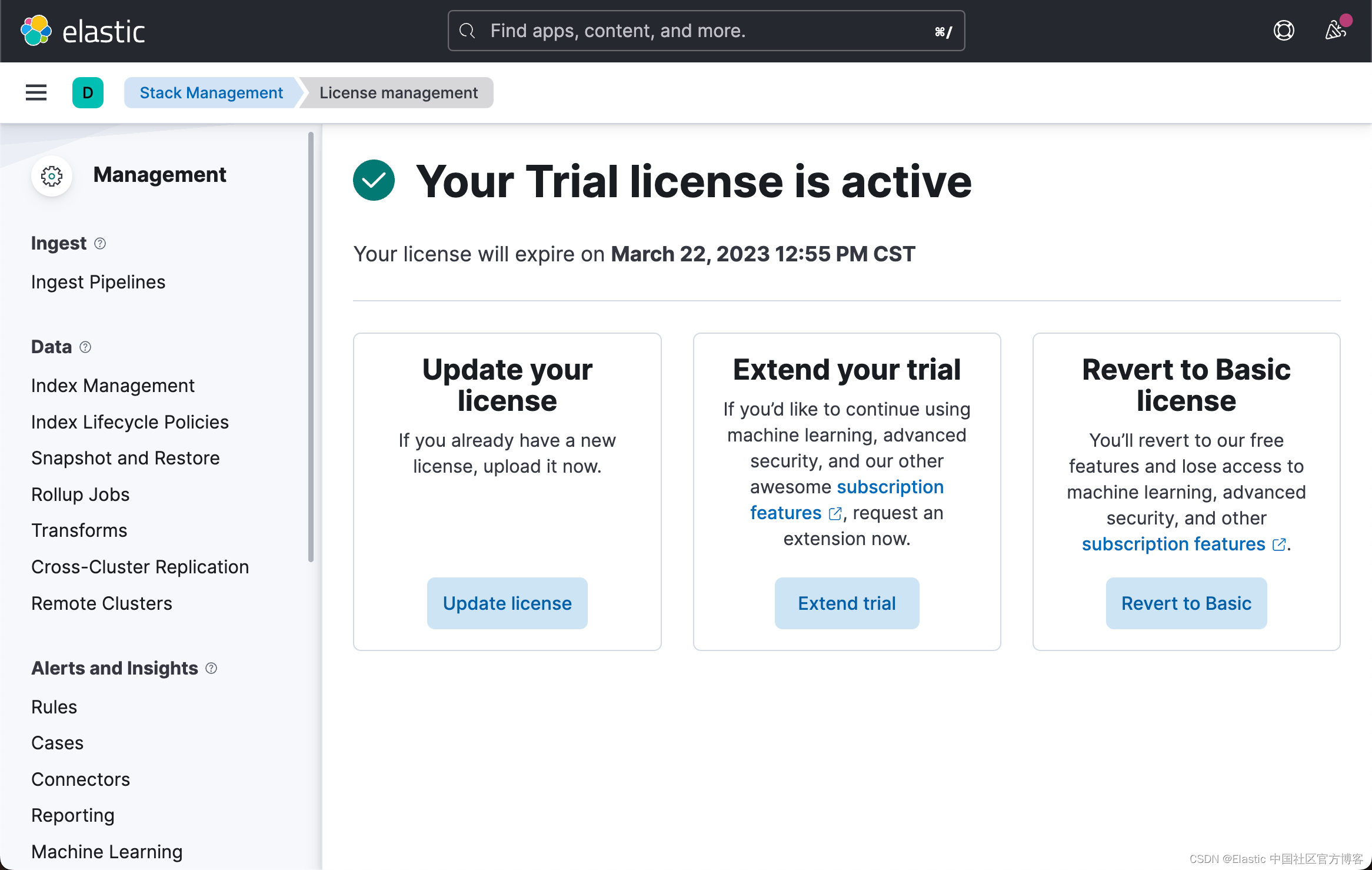
这样我们就启动了白金版试用功能。
我们再次运行上面的命令:
python main.py 这样,将下载模型并执行上传。 在上传过程中,你将在控制台上看到如下消息:

上面显示我们的下载及上传是成功的。
我们回到 Kibana 的界面进行查看:
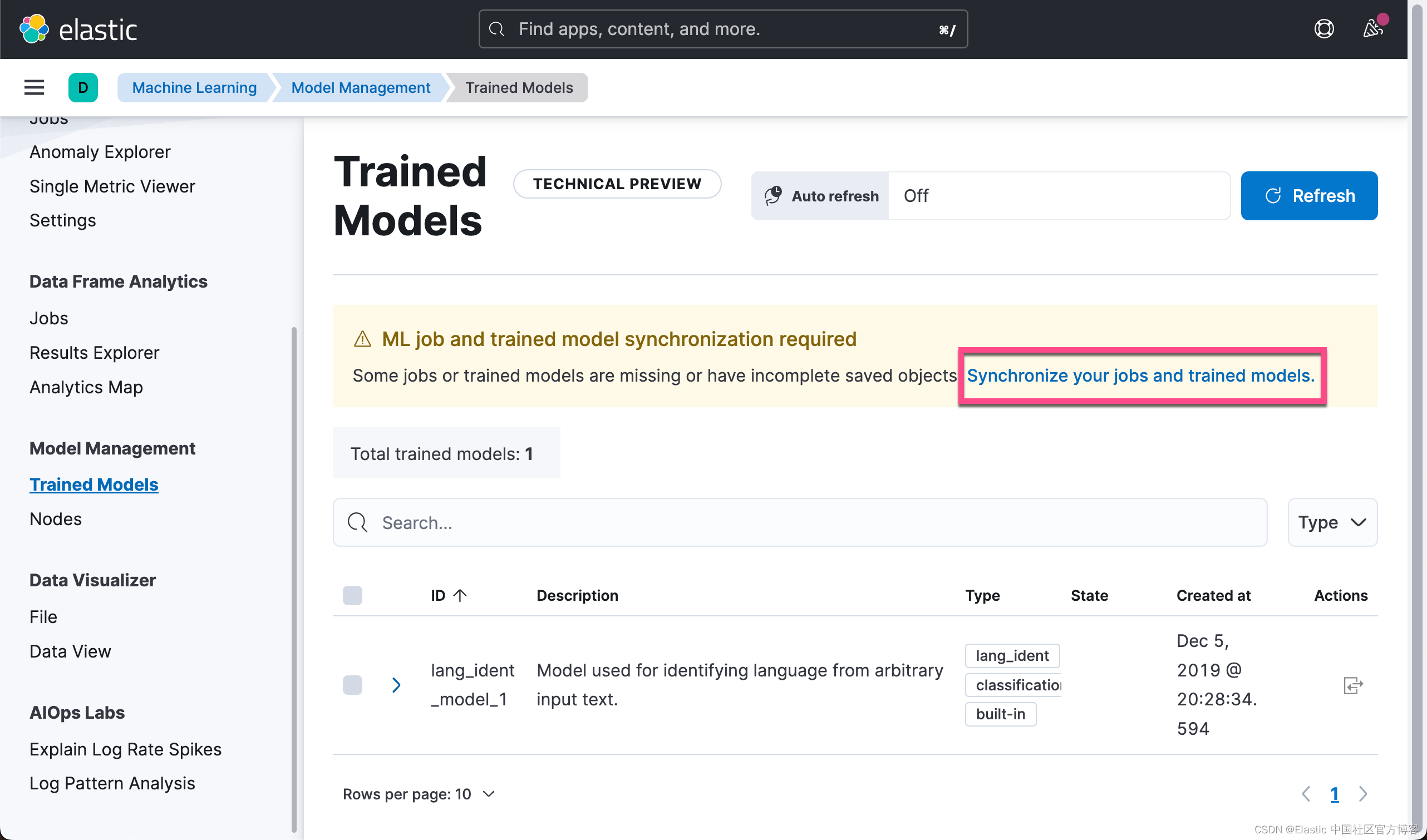
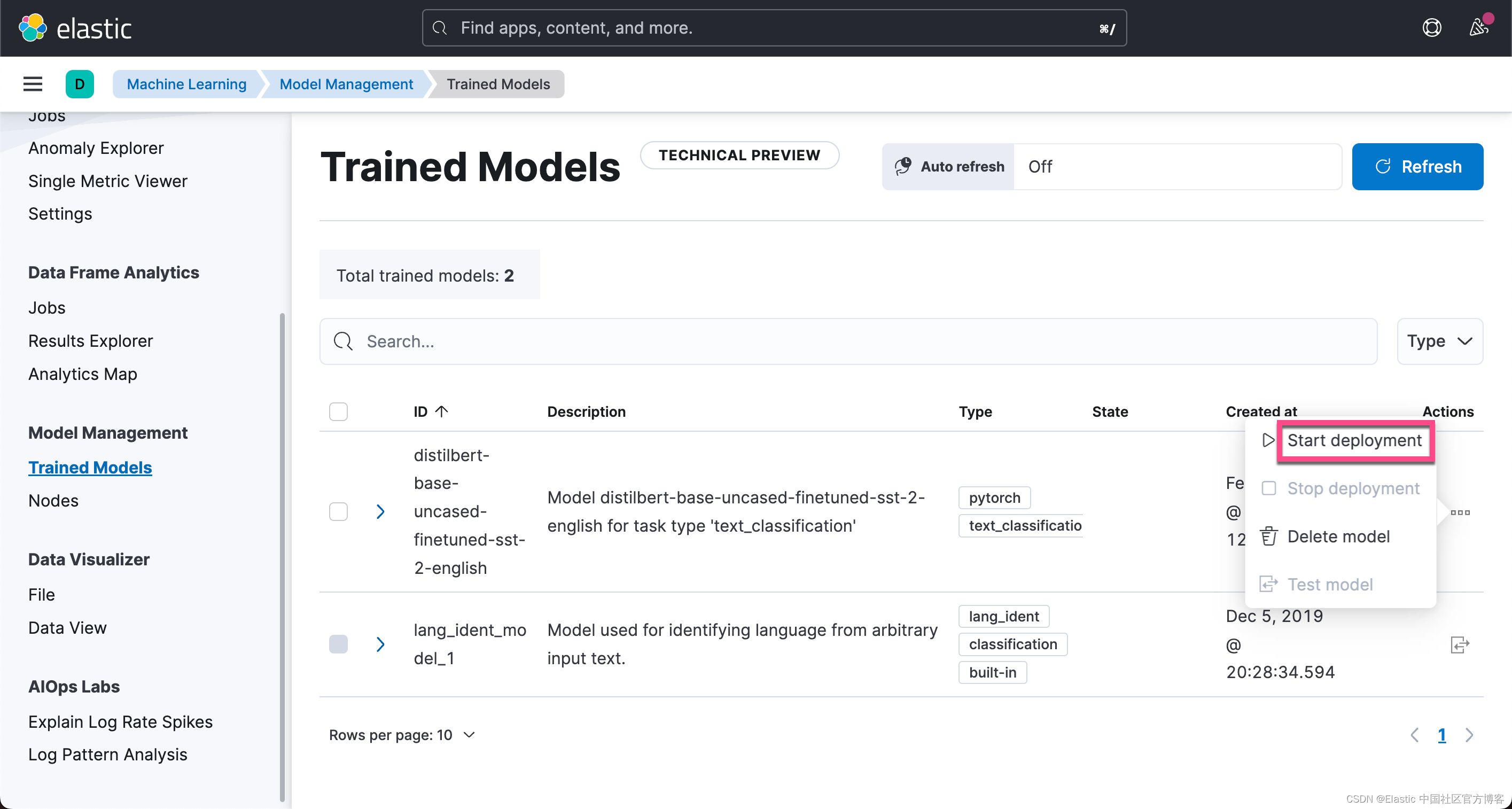
点击上面的 Start Deployment:
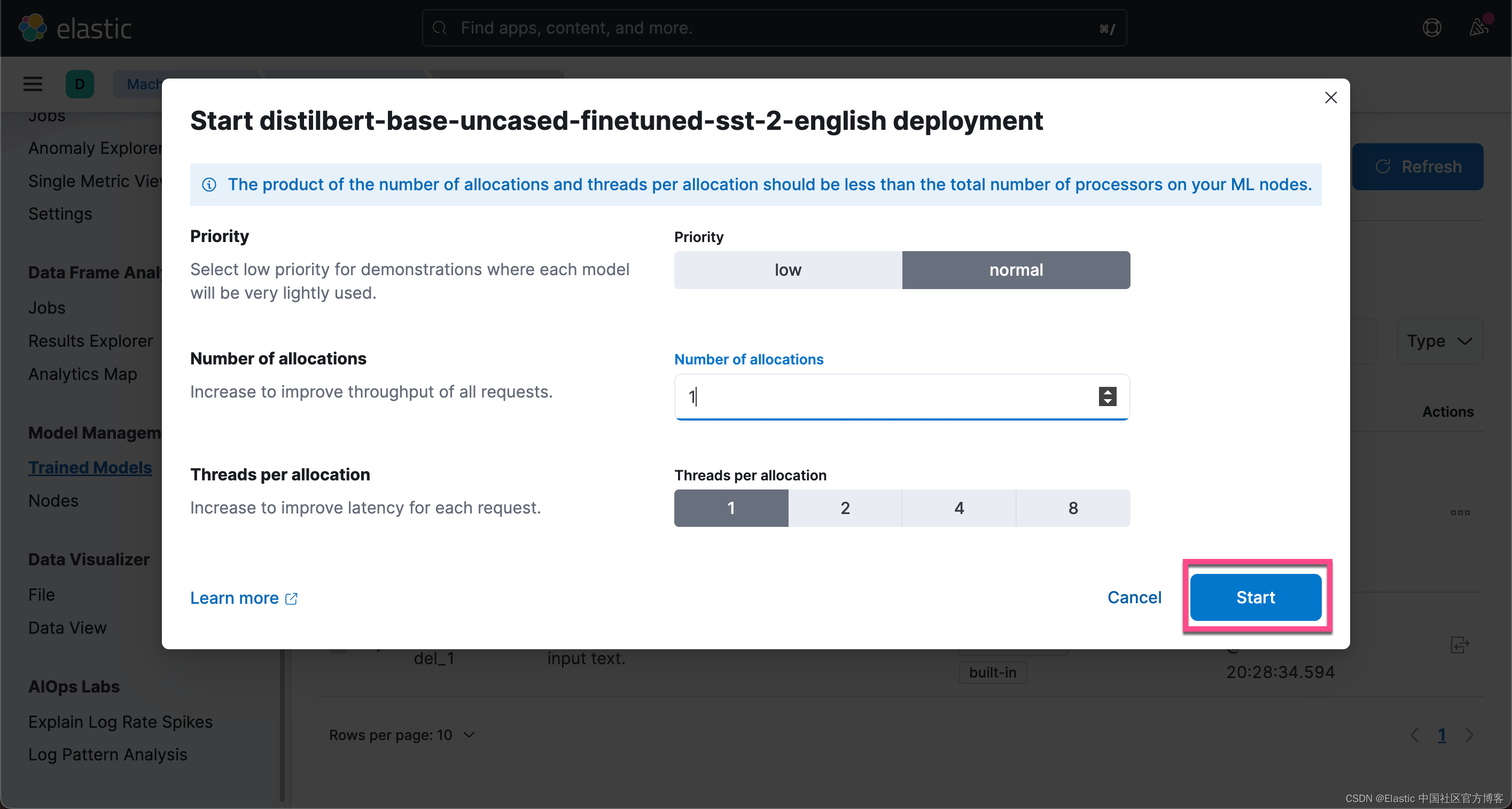
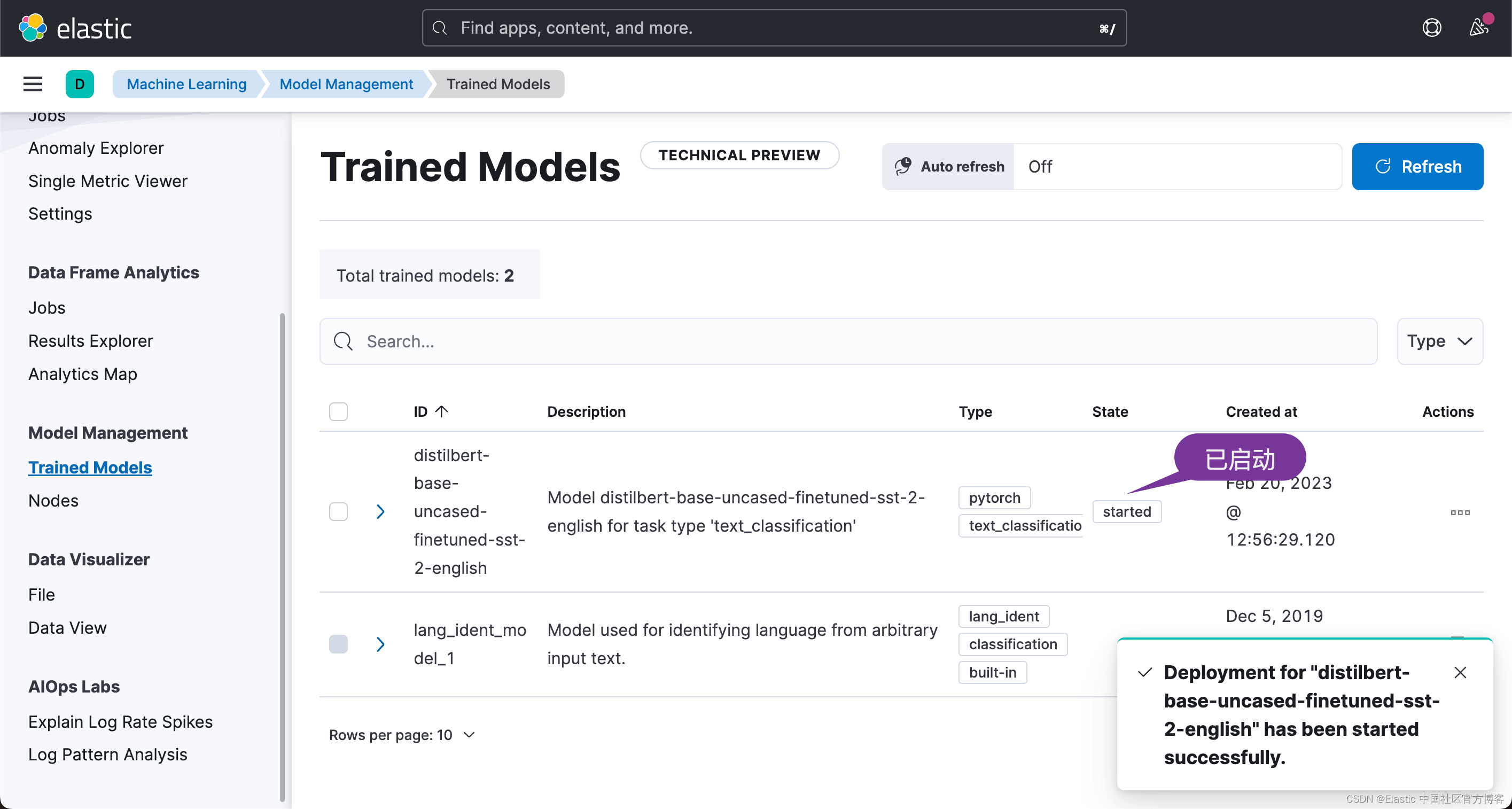
这样,我们就成功地启动了模型。我们可以通过如下的 API 来检查已经安装的模型:
GET /_ml/trained_models/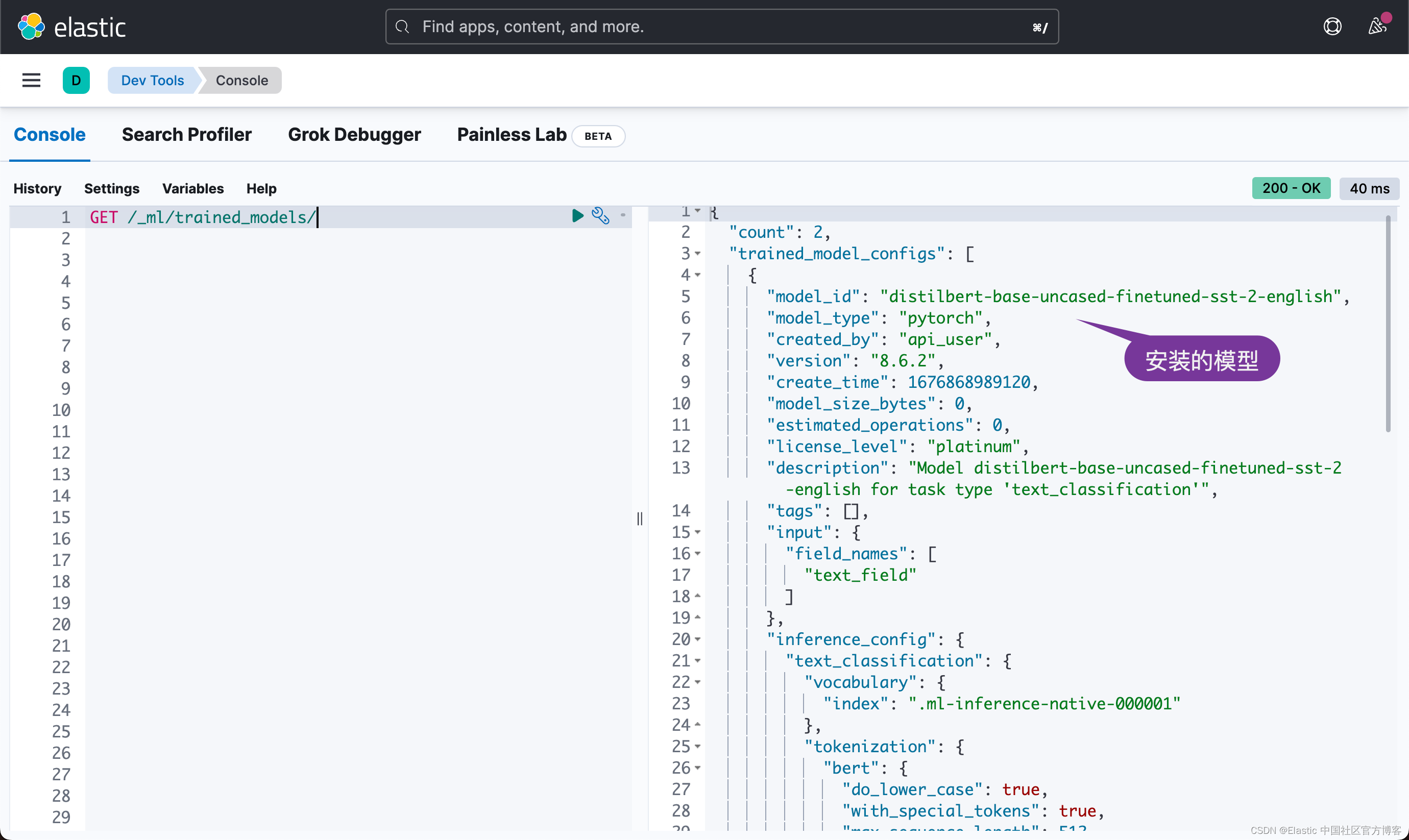
创建 index mapping
我们接下来创建如下的一个索引 mapping:
PUT survey
{
"mappings": {
"properties": {
"user": {
"type": "text"
},
"question_A": {
"properties": {
"question": {
"type": "text"
},
"answer": {
"type": "text"
}
}
},
"question_B": {
"properties": {
"question": {
"type": "text"
},
"answer": {
"type": "text"
}
}
},
"question_C": {
"properties": {
"question": {
"type": "text"
},
"answer": {
"type": "text"
}
}
},
"question_D": {
"properties": {
"question": {
"type": "text"
},
"answer": {
"type": "text"
}
}
}
}
}
}该索引的映射由 question 字段和 user 字段组成。 你可能会觉得奇怪,我有几个字段来定义 questions 而不是使用列表,但不幸的是,我在将推理处理器与列表一起使用时遇到了问题。
推理处理器 - inference processor
现在让我们进入最酷的部分。 通过索引 answer,我们将推断出每个 answer 的分类是什么。 在这部分中,我们将使用推理处理器,该处理器将使用 distilbert-base-uncased-finetuned-sst-2-english 模型,分析响应并在 form_answer_predicted 字段中设置分类。
对于每个答案,我们都会有评分,然后我添加了脚本处理器以根据答案生成最终用户满意度。
Ingest pipeline 将是这样的:
PUT _ingest/pipeline/text-answer-mode-analysis
{
"description": "Apply response analyzer using a sentiment analysis model",
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"target_field": "question_A.form_answer_predicted",
"field_map": {
"question_A.answer": "text_field"
}
}
},
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"target_field": "question_B.form_answer_predicted",
"field_map": {
"question_B.answer": "text_field"
}
}
},
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"target_field": "question_C.form_answer_predicted",
"field_map": {
"question_C.answer": "text_field"
}
}
},
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"target_field": "question_D.form_answer_predicted",
"field_map": {
"question_D.answer": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"source": """
int countPositive, countNegative = 0;
ArrayList list = new ArrayList();
list.add(ctx['question_A'].form_answer_predicted.predicted_value);
list.add(ctx['question_B'].form_answer_predicted.predicted_value);
list.add(ctx['question_C'].form_answer_predicted.predicted_value);
list.add(ctx['question_D'].form_answer_predicted.predicted_value);
for (int i = 0; i < list.size(); i++) {
if(list[i].equals("POSITIVE")) {
countPositive++;
} else {
countNegative++
}
}
if(countPositive > countNegative) {
ctx['user_satisfaction'] = "POSITIVE"
} else if (countPositive == countNegative) {
ctx['user_satisfaction'] = "NEUTRAL"
} else {
ctx['user_satisfaction'] = "NEGATIVE"
}
"""
}
}
]
}在上面,我们定义了一个叫做 text-answer-mode-analysis 的 ingest pipeline。它把几个问题都分别进行情绪分析,并最终使用 script 处理器来计算出这个人的情绪是:POSITIVE,NEGATIVE 或者是 NEUTRAL 的。
写入文档
我们现在准备索引数据。 我使用 Bulk API来索引数据并将管道设置为在索引时运行。
PUT survey/_bulk?pipeline=text-answer-mode-analysis
{"index": {"_id": 1}}
{"user":"xpto", "question_A": {"question":"How do you rate the customer service provided by the company?", "answer": "good"}, "question_B": {"question":"The information about the product/service was passed on clearly and correctly", "answer": "no"}, "question_C": {"question":"How would you describe our product(s)/service(s)?", "answer": "Useful"}, "question_D": {"question":"How satisfied are you with our company?", "answer": "Dissatisfied"}}
{"index": {"_id": 2}}
{"user":"xpto", "question_A": {"question":"How do you rate the customer service provided by the company?", "answer": "good"}, "question_B": {"question":"The information about the product/service was passed on clearly and correctly", "answer": "yes"}, "question_C": {"question":"How would you describe our product(s)/service(s)?", "answer": "Useful"}, "question_D": {"question":"How satisfied are you with our company?", "answer": "Satisfied"}}
{"index": {"_id": 3}}
{"user":"xpto", "question_A": {"question":"How do you rate the customer service provided by the company?", "answer": "bad"}, "question_B": {"question":"The information about the product/service was passed on clearly and correctly", "answer": "no"}, "question_C": {"question":"How would you describe our product(s)/service(s)?", "answer": "Very expensive"}, "question_D": {"question":"How satisfied are you with our company?", "answer": "Dissatisfied"}}请注意,在上面的每个文档中,它都含有四个问题,并含有相应的答案。
我们可以通过如下命令来查看被摄入的文档:
GET survey/_search?filter_path=**.hits上面命令搜索的结果是:
{
"hits": {
"hits": [
{
"_index": "survey",
"_id": "1",
"_score": 1,
"_source": {
"question_C": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9997634803424444,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How would you describe our product(s)/service(s)?",
"answer": "Useful"
},
"question_D": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9997315864531746,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How satisfied are you with our company?",
"answer": "Dissatisfied"
},
"question_A": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9998161198125766,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How do you rate the customer service provided by the company?",
"answer": "good"
},
"question_B": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9964459731735253,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "The information about the product/service was passed on clearly and correctly",
"answer": "no"
},
"user": "xpto",
"user_satisfaction": "NEUTRAL"
}
},
{
"_index": "survey",
"_id": "2",
"_score": 1,
"_source": {
"question_C": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9997634803424444,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How would you describe our product(s)/service(s)?",
"answer": "Useful"
},
"question_D": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9997212937948691,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How satisfied are you with our company?",
"answer": "Satisfied"
},
"question_A": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9998161198125766,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How do you rate the customer service provided by the company?",
"answer": "good"
},
"question_B": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9997805442484351,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "The information about the product/service was passed on clearly and correctly",
"answer": "yes"
},
"user": "xpto",
"user_satisfaction": "POSITIVE"
}
},
{
"_index": "survey",
"_id": "3",
"_score": 1,
"_source": {
"question_C": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.965237853665764,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How would you describe our product(s)/service(s)?",
"answer": "Very expensive"
},
"question_D": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9997315864531746,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How satisfied are you with our company?",
"answer": "Dissatisfied"
},
"question_A": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9997823345695842,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How do you rate the customer service provided by the company?",
"answer": "bad"
},
"question_B": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9964459731735253,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "The information about the product/service was passed on clearly and correctly",
"answer": "no"
},
"user": "xpto",
"user_satisfaction": "NEGATIVE"
}
}
]
}
}在进行搜索时,你会看到在每个问题中都生成了带有分类的字段,字段 form_answer_predicted。
"question_B": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9964459731735253,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},这个表示情绪识别的准确性。
另外,我们的通用分类字段 user_satisfaction 也已创建。 在下面的示例中,由于正面和负面预测的数量相同,我们的状态为“NEUTRAL”:
"_source": {
"question_C": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9997634803424444,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How would you describe our product(s)/service(s)?",
"answer": "Useful"
},
"question_D": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9997315864531746,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How satisfied are you with our company?",
"answer": "Dissatisfied"
},
"question_A": {
"form_answer_predicted": {
"predicted_value": "POSITIVE",
"prediction_probability": 0.9998161198125766,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "How do you rate the customer service provided by the company?",
"answer": "good"
},
"question_B": {
"form_answer_predicted": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9964459731735253,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
},
"question": "The information about the product/service was passed on clearly and correctly",
"answer": "no"
},
"user": "xpto",
"user_satisfaction": "NEUTRAL"
}
}好了,今天的文章就写到这里。希望你通过这个例子能对 Elastic Stack 所提供的 NLP 有更多的认识,并在你将来的应用中使用到。