作者:Peter Titov

对于任何组织来说,个人身份信息 (Personally Identifiable information, PII) 合规性都是一个日益严峻的挑战。 无论你是在电子商务、银行、医疗保健还是其他数据敏感的领域,PII 都可能会在无意中被捕获和存储。 拥有结构化日志,可以轻松快速识别、删除和保护敏感数据字段; 但非结构化消息又如何呢? 或者也许是呼叫中心转录?
Elasticsearch 凭借其在机器学习领域的长期经验,提供了各种引入自定义模型的选项,例如大语言模型 (LLM),并提供了自己的模型。 这些模型将有助于实施 PII 编辑。
如果你想了解有关自然语言处理、机器学习和 Elastic 的更多信息,请务必查看以下相关文章:
- Elasticsearch 中使用 PyTorch 进行现代自然语言处理简介
- Elastic Redact 处理器文档
- Elastic Learned Sparse Encoder 简介:Elastic 用于语义搜索的 AI 模型
- 访问 Elastic 中的机器学习模型
在本博客中,我们将向你展示如何利用 Elasticsearch 在机器学习中加载经过训练的模型的能力以及 Elastic 摄取管道的灵活性来设置 PII 修订。
具体来说,我们将逐步建立一个用于人员和位置识别的命名实体识别 (NER)模型,以及部署用于自定义数据识别和删除的编辑处理器。 然后,所有这些都将与摄取管道相结合,我们可以在其中使用 Elastic 机器学习和数据转换功能从数据中删除敏感信息。
加载训练好的模型
在开始之前,我们必须将 NER 模型加载到 Elasticsearch 集群中。 这可以通过 Docker 和 Elastic Eland 客户端轻松完成。 从命令行,让我们通过 git 安装 Eland 客户端:
git clone https://github.com/elastic/eland.git导航到最近下载的客户端:
cd eland/现在让我们构建客户端:
docker build -t elastic/eland .从这里,你就可以将经过训练的模型部署到 Elastic 机器学习节点! 请务必替换你的用户名、密码、es-cluster-hostname 和 esport。
如果你使用 Elastic Cloud 或已签名证书,只需运行以下命令:
docker run -it --rm --network host elastic/eland eland_import_hub_model --url https://<username>:<password>@<es-cluster-hostname>:<esport>/ --hub-model-id dslim/bert-base-NER --task-type ner --start如果你使用自签名证书,请运行以下命令:
docker run -it --rm --network host elastic/eland eland_import_hub_model --url https://<username>:<password>@<es-cluster-hostname>:<esport>/ --insecure --hub-model-id dslim/bert-base-NER --task-type ner --start从这里,你将见证 Eland 客户端从 HuggingFace 下载经过训练的模型并自动将其部署到你的集群中!

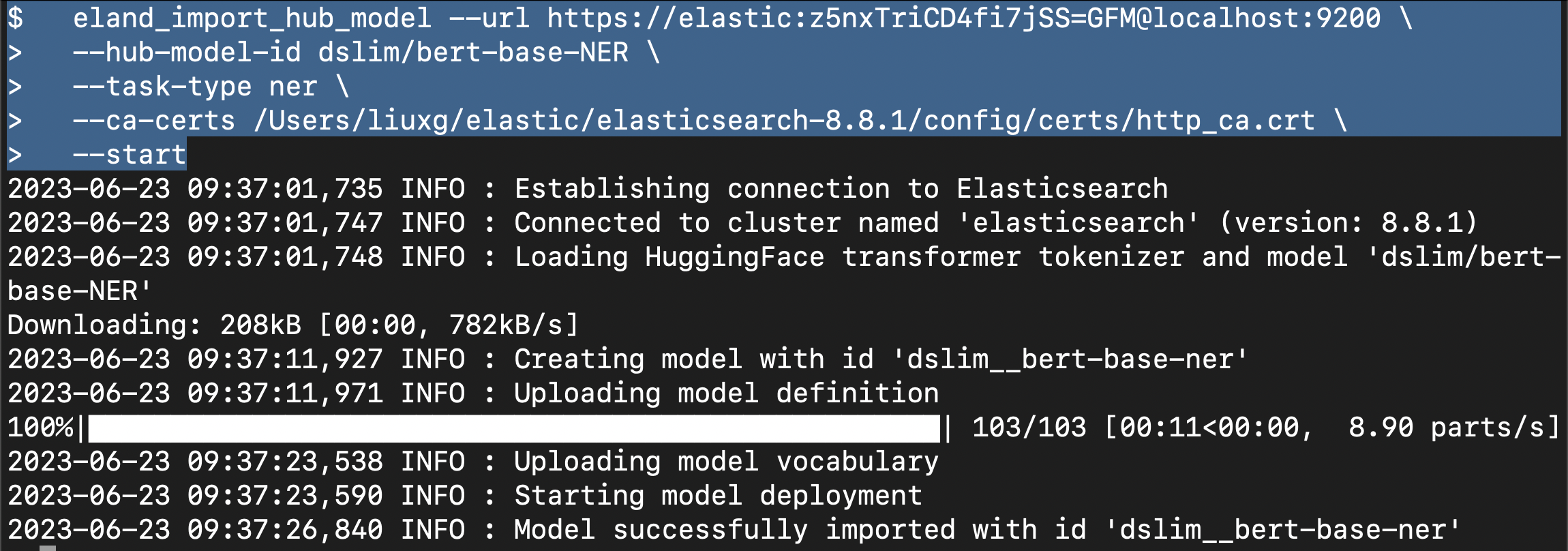
针对我的情况,我更倾向于使用已经发布好的 eland。详细的安装步骤,请参阅文章 “Elasticsearch:如何在 Elastic 中实现图片相似度搜索”。我们可以使用如下的命令来进行:
eland_import_hub_model --url https://<user>:<password>@<hostname>:<port> \
--hub-model-id dslim/bert-base-NER \
--task-type ner \
--ca-certs <your certificate> \
--start在我的电脑上,我使用:
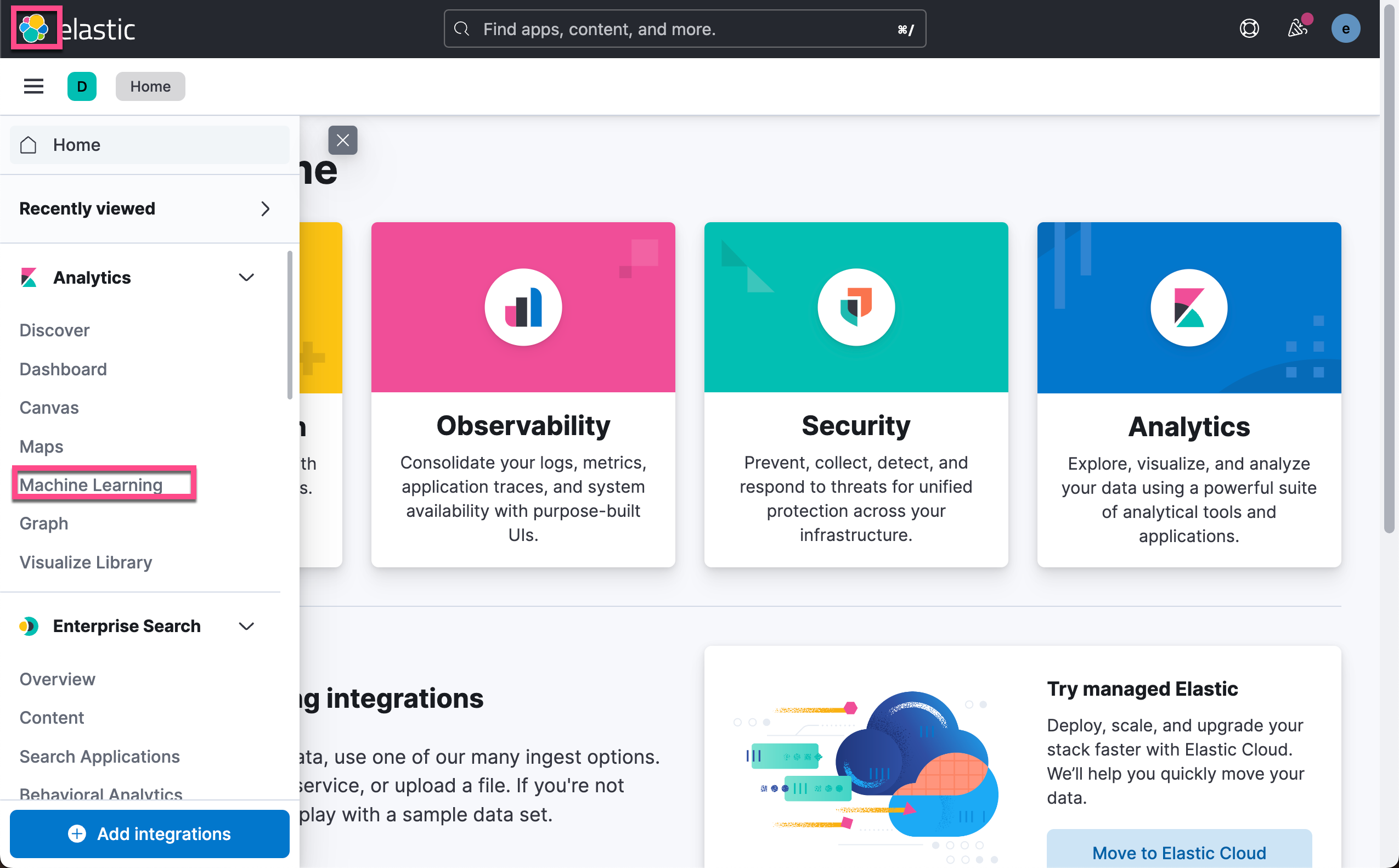
通过机器学习概述 UI “Synchronize your jobs and trained models.” 单击蓝色超链接来同步新加载的训练模型。
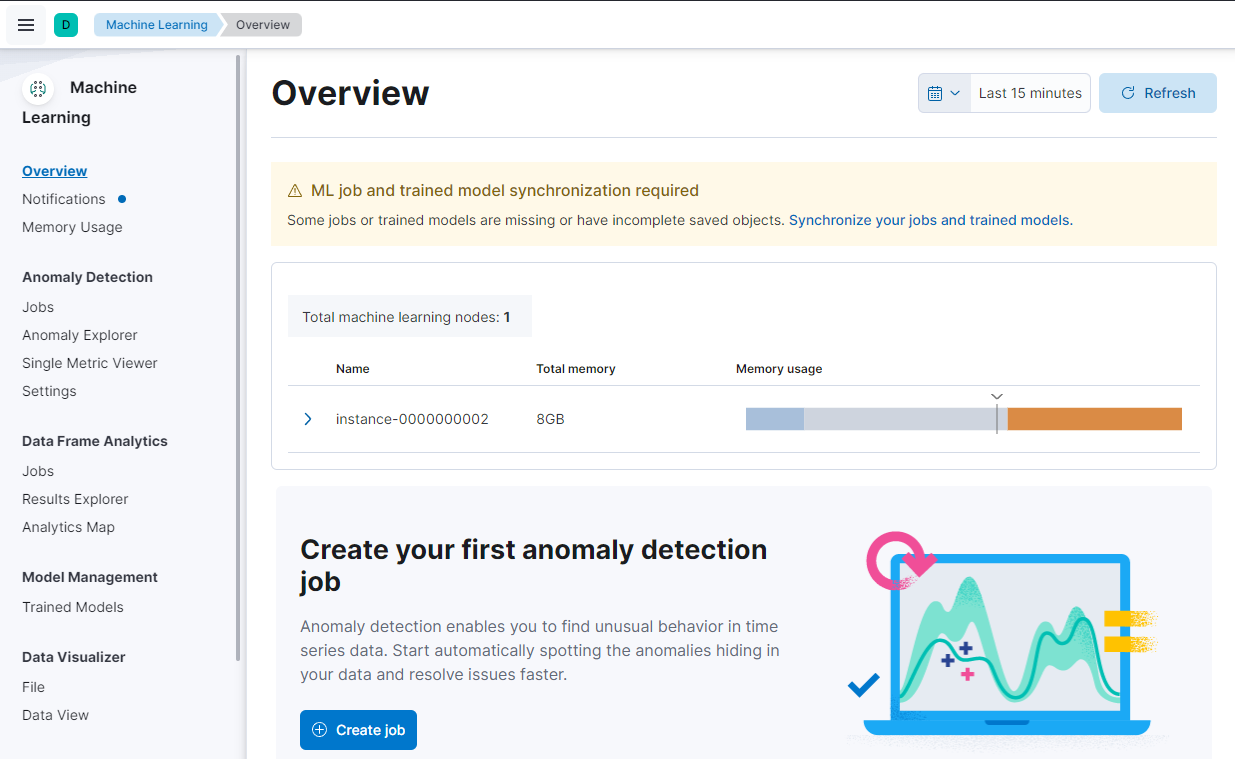

就是这样! 恭喜,你刚刚将第一个经过训练的模型加载到 Elasticsearch 中!
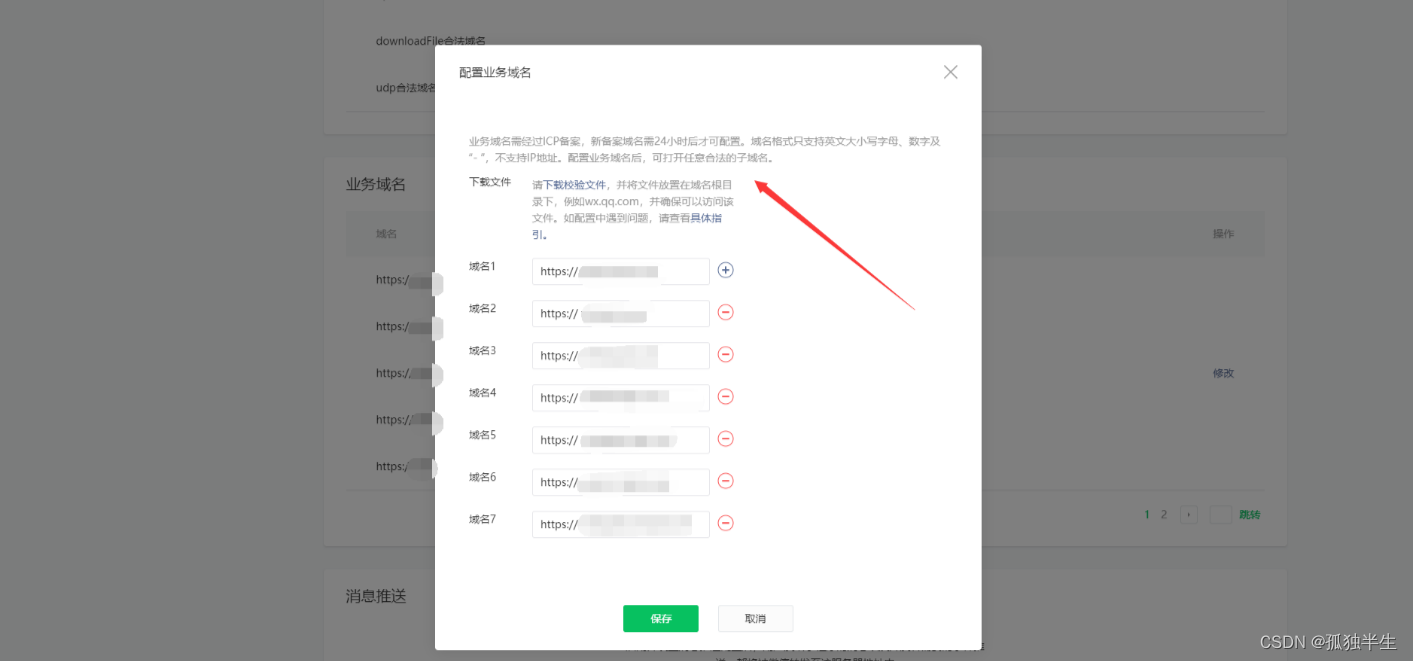
创建编辑处理器和摄取管道
在 DevTools 中,我们配置 redact 处理器和推理处理器,以利用我们刚刚加载的 Elastic 训练模型。 这将创建一个名为 redact 的摄取管道,然后我们可以使用它从我们希望的任何字段中删除敏感数据。 在此示例中,我将重点关注 “message” 字段。 注意:在撰写本文时,redact 处理器处于实验阶段,必须通过 DevTools 创建。
Redact 处理器简介:Redact 处理器使用 Grok 规则引擎来模糊输入文档中与给定 Grok 模式匹配的文本。 该处理器可用于通过配置检测电子邮件或 IP 地址等已知模式来隐藏个人识别信息 (PII)。 与 Grok 模式匹配的文本将替换为可配置字符串,例如匹配电子邮件地址的 <EMAIL>,或者如果愿意,只需将所有匹配项替换为文本 <REDACTED>。
我们在 Dev Tools 下打入如下的命令:
PUT _ingest/pipeline/redact
{
"processors": [
{
"set": {
"field": "redacted",
"value": "{{{message}}}"
}
},
{
"inference": {
"model_id": "dslim__bert-base-ner",
"field_map": {
"message": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"source": """
String msg = ctx['message'];
for (item in ctx['ml']['inference']['entities']) {
msg = msg.replace(item['entity'], '<' + item['class_name'] + '>')
}
ctx['redacted']=msg
"""
}
},
{
"redact": {
"field": "redacted",
"patterns": [
"%{EMAILADDRESS:EMAIL}",
"%{IP:IP_ADDRESS}",
"%{CREDIT_CARD:CREDIT_CARD}",
"%{SSN:SSN}",
"%{PHONE:PHONE}"
],
"pattern_definitions": {
"CREDIT_CARD": """\d{4}[ -]\d{4}[ -]\d{4}[ -]\d{4}""",
"SSN": """\d{3}-\d{2}-\d{4}""",
"PHONE": """\d{3}-\d{3}-\d{4}"""
}
}
},
{
"remove": {
"field": [
"ml"
],
"ignore_missing": true,
"ignore_failure": true
}
}
],
"on_failure": [
{
"set": {
"field": "failure",
"value": "pii_script-redact"
}
}
]
}好的,但是每个处理器的真正作用是什么? 让我们在这里详细介绍每个处理器:
- SET 处理器创建 redacted 字段,该字段从 message 字段复制过来,并稍后在管道中使用。
- INFERENCE 处理器调用我们加载的 NER 模型,用于消息字段来识别名称、位置和组织。
- 然后,SCRIPT 处理器从消息字段中替换编辑字段内检测到的实体。
- 我们的 REDACT 处理器使用 Grok 模式来识别我们希望从编辑字段(从 message 字段复制而来)中删除的任何自定义数据集。
- REMOVE 处理器从索引中删除无关的 ml.* 字段; 请注意,一旦我们验证数据被正确编辑,我们就会向该处理器添加 “message”。
- ON_FAILURE / SET 处理器会捕获任何错误,以防万一出现错误。
分割你的 PII
现在已经配置了包含所有必要步骤的摄取管道,让我们开始测试从文档中删除敏感数据的效果。 导航到 Stack Management,选择 Ingest Pipelines 并搜索redact,然后单击结果。



在这里,我们将通过添加一些文档来测试我们的管道。 下面是一个示例,你可以复制并粘贴以确保一切正常工作。
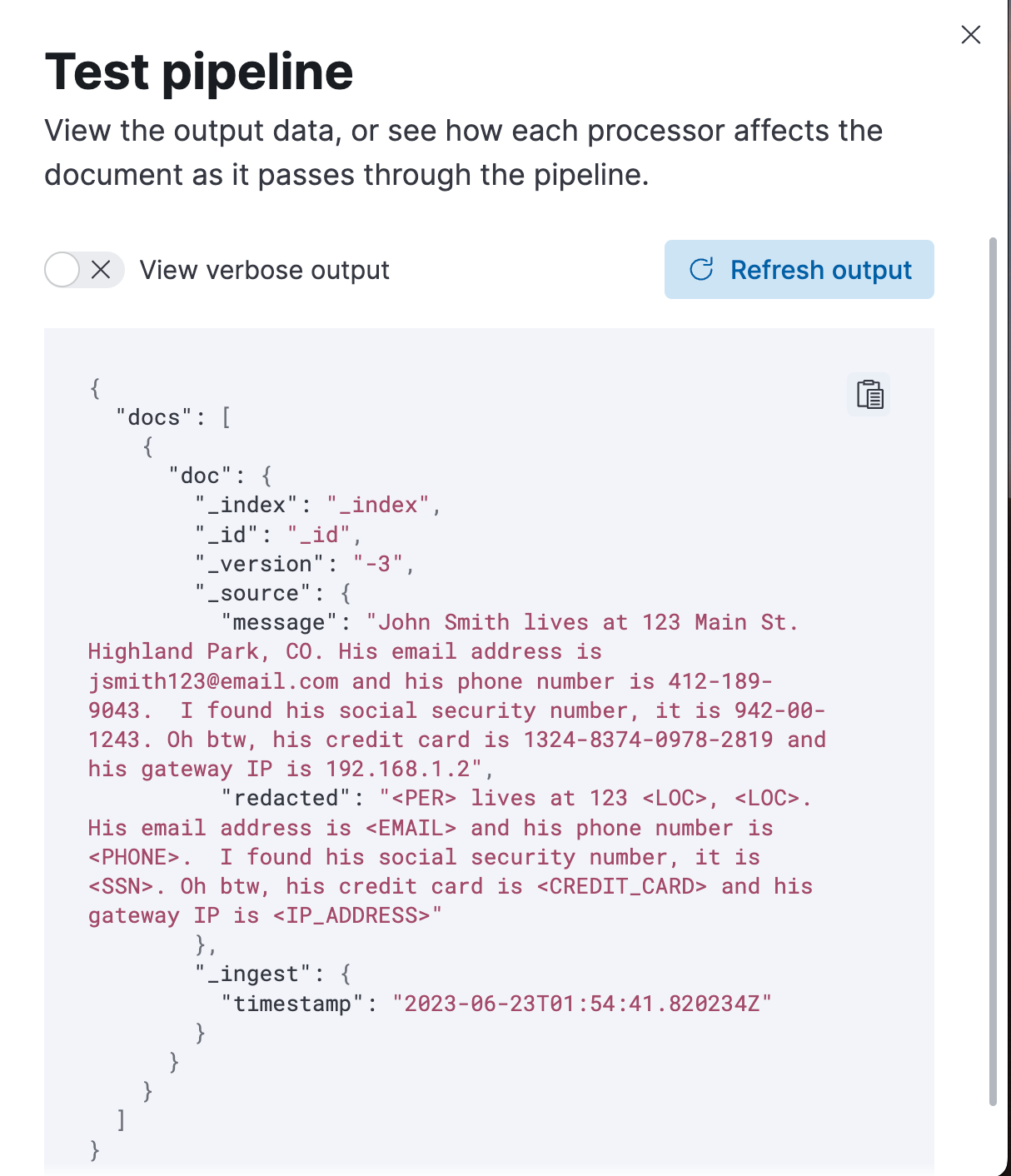
{"_source":{"message": "John Smith lives at 123 Main St. Highland Park, CO. His email address is jsmith123@email.com and his phone number is 412-189-9043. I found his social security number, it is 942-00-1243. Oh btw, his credit card is 1324-8374-0978-2819 and his gateway IP is 192.168.1.2"}}

只需按下 “Run the pipeline” 按钮,您你看到以下输出:
下一步是什么?
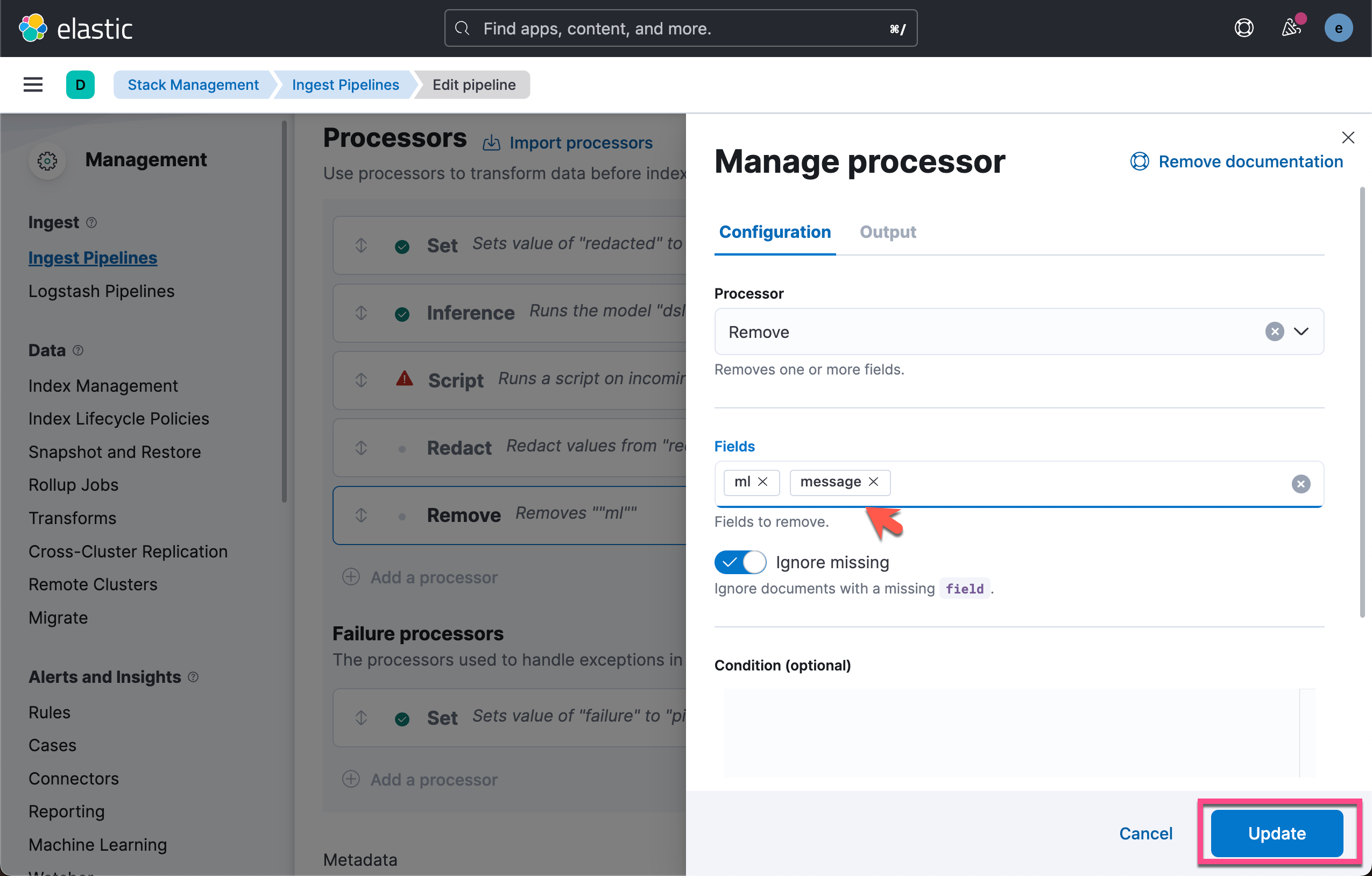
将此摄取管道添加到要建立索引的数据集并验证其是否满足预期后,你可以添加要删除的消息字段,以便不会对 PII 数据建立索引。 只需更新你的 REMOVE 处理器以包含 message 字段并再次模拟即可仅看到已编辑的字段。
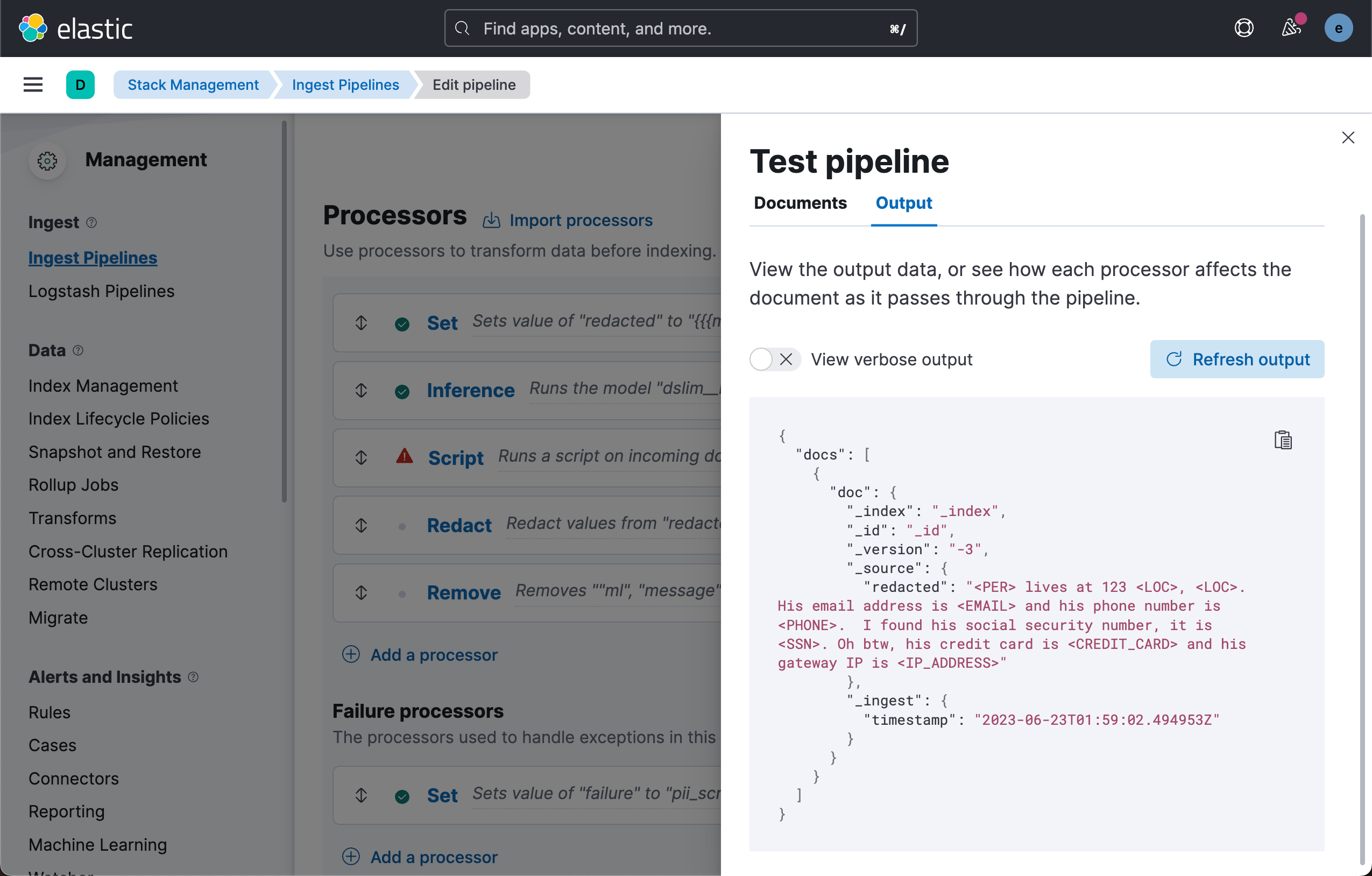
再次运行测试 pipeline。我们发现 message 字段消失了。
结论
通过这种分步方法,你现在已准备好并能够检测和编辑整个索引中的任何敏感数据。
以下是我们所讨论内容的快速回顾:
- 将预训练的命名实体识别模型加载到 Elastic 集群中
- 配置 Redact 处理器和推理处理器,以在数据摄取期间使用经过训练的模型
- 测试示例数据并修改摄取管道以安全删除个人身份信息
准备好开始了吗? 注册 Elastic Cloud 并尝试我上面概述的特性和功能,以从 OpenTelemetry 数据中获得最大价值和可见性。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用了第三方生成式人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。