文章目录
- 官方Demo
- Query
- Term
- StandardAnalyzer
- 源码分析
- QueryBuilder.createFieldQuery
- StandardTokenizer
- StandardTokenizerImpl
官方Demo
我们先看官方提供的demo代码,从使用demo运行一遍,看看分词之后的结果,然后再对源码进行研究。分词的核心代码其实就是这几句:
java">Analyzer analyzer = new StandardAnalyzer();
QueryParser parser = new QueryParser(field, analyzer);
Query query = parser.parse(line);
代码运行后,我们发现分词的结果存储在变量query 。
Query
Query对应实现类BooleanQuery。分词之后的结果存储于变量clauses(Collections)中,里面的元素就是分词之后的每个单词即BooleanClause实例。
BooleanClause类有一个变量为query(TermQuery)–>term(Term),这个term就是我们的单词了。

Term
field:索引字段
bytes:单词字符串对应的byte[]
StandardAnalyzer
官方的标准分词器StandardAnalyzer,它使用了标准分词器对应的分词算法StandardTokenizer,然后再加上忽略大小写LowerCaseFilter和停用词StopFilter的过滤功能TokenFilter。
java">@Override
protected TokenStreamComponents createComponents(final String fieldName) {
final Tokenizer src;
if (getVersion().onOrAfter(Version.LUCENE_4_7_0)) {
StandardTokenizer t = new StandardTokenizer();
t.setMaxTokenLength(maxTokenLength);
src = t;
} else {
StandardTokenizer40 t = new StandardTokenizer40();
t.setMaxTokenLength(maxTokenLength);
src = t;
}
TokenStream tok = new StandardFilter(src);
tok = new LowerCaseFilter(tok);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) {
int m = StandardAnalyzer.this.maxTokenLength;
if (src instanceof StandardTokenizer) {
((StandardTokenizer)src).setMaxTokenLength(m);
} else {
((StandardTokenizer40)src).setMaxTokenLength(m);
}
super.setReader(reader);
}
};
}
源码分析
java">QueryParser parser = new QueryParser(field, analyzer);
Query query = parser.parse(line);
QueryParser.parse是继承QueryParserBase,源码如下:
new FastCharStream(new StringReader(query)),应该就是把字符串转化为lucene优化过的字节流了;ReInit是重新初始化QueruParser。
接下来是TopLevelQuery,然后看关键代码,我们可以直接跳到QueryBuilder.createFieldQuery

QueryBuilder.createFieldQuery
在QueryBuilder这个实现类中,createFieldQuery会生成带有分词结果的Query对象。
为了方便理解,我们可以先看代码执行后,CachingTokenFilter会缓存分词结果,放在一个cache链表,里面的每个元素就是经过分词之后的每个单词。
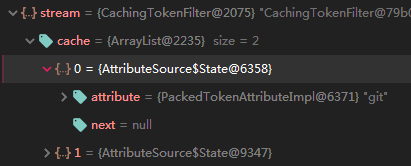
最后,再把stream缓存的每一个单词转化为对应一个Query实例,这个方法就不细说了,有兴趣的可以自己去看源码。

analyzeMultiBoolean这个方法其实就是如何将CachingTokenFilter的分词结果传输到BooleanQuery
-------------------------------继续看源码----------------------------------
首先,看第一部分代码,都是一些初始化,包括分词器Analyzer,还有缓存分词结果的CachingTokenFilter对象stream变量

然后,第二部分代码,stream.incrementToken()这是分词的重点,进入这个方法

进入了之后,我们可以看到,像我们上面看到的,会有一个cache链表来存储分词结果。然后,再转化为一个iterator

那么,显而易见,分词是在fillCache()这个方法块里完成的了。

StandardTokenizer
再深入研究,发现来到了StandardTokenizer类,这里我们需要知道scanner是实现类StandardTokenizerImpl,我们先看scanner.getText(termAtt)方法

StandardTokenizerImpl
scanner.getText(termAtt)这里的变量t,即传入的参数termAtt有一个属性termBuffer,是一个char[],看名字也就可以知道跟Term是类似的作用,存放单词的。可以看到,方法的功能是从另一个char数组,根据起始位置和长度来获取当前的单词。那么,其实完成分词的关键就是计算zzStartRead和zzStartRead。

这个两个成员变量的计算,跟踪源码,发现是在scanner.getNextToken()这里实现的,也就是StandardTokenizerImpl实现类的getNextToken方法了。所以,最关键的分词算法就是在这里实现,我们可以根据自己的实际情况设计自己的分词算法。
最后,由于根据上面提到的标准分词器StandardAnalyzer还使用忽略大小写和停用词的功能,所以,StandardTokenizerImpl分词之后的单词还会进行大小写处理和停用词过滤。


欢迎关注同名公众号:“我就算饿死也不做程序员”。
交个朋友,一起交流,一起学习,一起进步。







